Unidad 1
Gestión de Base de Datos
Indice
Evaluación Diagnostica de Base de Datos
1.- INTRODUCCIÓN
Que es PhpMyAdmin
Es un software de código abierto diseñado para
administrar y gestionar bases de datos con SQL (lenguaje de
consulta estructurada), con una interface gráfica usando PHP
(Hypertext Preprocessor: es un lenguaje de código abierto muy
popular especialmente adecuado para el desarrollo web y que puede
ser incrustado en HTML.)
Se pueden crear bases de datos, tablas, consultas, búsquedas de
datos.
PhpMyAdmin fue iniciado en 1998, pesando en una
red administrativa, fue tomando forma para que sea lo mas simple
posible, en 2001, fue concedido a SourceForge.org, actualmente
esta en 55 idiomas.
En este curso se trabaja bajo LINUX, usando LAMP, sin embargo
podemos instalar PhpMyAdmin en Windows 10 x64, que tiene por
nombre wampserver3.3.2.exe
descargar para Windows 10 tamaño de archivo
descarga 591.5 Mb win10.zip dentro de este archivo
encontraras todas las actualizaciones de visual c, para
redistribución npp.7.9.1.installer.exe (notepad ++)
wampserver3.2.2_x64.exe, y el url donde se obtuvieron los
programas, excepto notepad++, con una salvedad, ya no es necesario
especificar immodb para MariaDB, ya lo tiene por defecto, a
comparación de versiones anteriores, el proceso del video
anteriormente es lo mismo, la instalación para Windows 8-8,1 es
igual solo que cambian algunos archivos para Visual C++, y el
instalador de PhpMyAdmin tiene por nombre wampserver2.2e-php5.4.3-httpd-2.4.2-mysql5.5.24-x64.exe
la descarga para Windows 8-8.1 tamaño del archivo descarga 177.75
Mb win8.1.zip
para windows 7 use el siguiente enlace que explica la
instalación wamp_windows7
para realizar nuestras pruebas esta bien pero
para un entorno de producción, debemos de tener en consideración
la seguridad para ello los usuarios de windows (cualquier versión)
deberán de consultar esta pagina de PhpMyAdmin
Aquí otra pagina de configuración PhpMyAdmin
(en ingles)
es indispensable tenerlo instalado para
poder seguir con el curso
Realiza el siguiente Test 1 Unidad 1
Ventajas
Usa 10 MB de espacio en disco, por lo que es muy ligero en
espacio de disco, y tiene todos los idiomas disponibles.
Es opensource (GNU)
Es por default PhpMyAdmin en los hostings de la nube.
Es muy popular y fácil de usar
la tendencia es muy interesante con sistemas de sistemas
abiertos (open source) Trend
Google
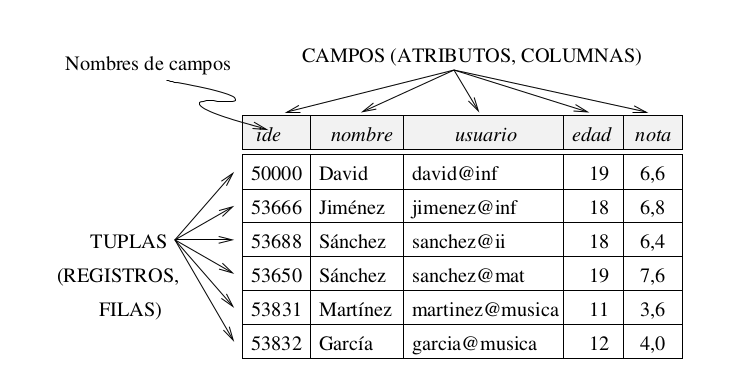
¿Qué es una base de datos?
Una base de datos es una recopilación organizada de información o
datos estructurados, que normalmente se almacena de forma
electrónica en un sistema informático. Normalmente, una base de
datos está controlada por un sistema de gestión de bases de datos
(DBMS). En conjunto, los datos y el DBMS, junto con las
aplicaciones asociadas a ellos, reciben el nombre de sistema de
bases de datos, abreviado normalmente a simplemente base de datos.
Los datos de los tipos más comunes de bases de datos en
funcionamiento actualmente se suelen utilizar como estructuras de
filas y columnas en una serie de tablas para aumentar la eficacia
del procesamiento y la consulta de datos. Así, se puede acceder,
gestionar, modificar, actualizar, controlar y organizar fácilmente
los datos. La mayoría de las bases de datos utilizan un lenguaje
de consulta estructurada (SQL) para escribir y consultar datos.
¿Qué es el
lenguaje de consulta estructurada (SQL)?
El SQL es un lenguaje de programación que
utilizan casi todas las bases de datos relacionales para
consultar, manipular y definir los datos, además de para
proporcionar control de acceso. El SQL se desarrolló por primera
vez en IBM en la década de 1970 con Oracle como uno de los
principales contribuyentes, lo que dio lugar a la implementación
del estándar ANSI SQL. El SQL ha propiciado muchas ampliaciones de
empresas como IBM, Oracle y Microsoft. Aunque el SQL se sigue
utilizando mucho hoy en día, están empezando a aparecer nuevos
lenguajes de programación.
¿Cuál es la diferencia entre una base de datos y
una hoja de cálculo?
Tanto las bases de datos como las hojas de
cálculo (como Microsoft Excel) son modos cómodos de almacenar
información. Las principales diferencias entre los dos son:
Cómo se almacenan y se manipulan los datos
Quién puede acceder a los datos
Cuántos datos pueden almacenarse
Las hojas de cálculo se diseñaron originalmente
para un usuario y sus características así lo reflejan. Son
perfectas para un único usuario o para un pequeño número de
usuarios que no necesiten hacer una gran manipulación de datos
increíblemente complicada. Las bases de datos, por otro lado,
están diseñadas para contener recopilaciones mucho más grandes de
información organizada, a veces en cantidades masivas. Las bases
de datos permiten que muchos usuarios accedan y consulten los
datos de forma rápida y segura al mismo tiempo mediante una
lógica, y un lenguaje muy complejos.
Tipos
de bases de datos (1)
Existen muchos tipos diferentes de bases de
datos. La mejor base de datos para una organización específica
depende de cómo pretenda la organización utilizar los datos.
Bases de datos relacionales
Las bases de datos relacionales se hicieron
predominantes en la década de 1980. Los elementos de una base de
datos relacional se organizan como un conjunto de tablas con
columnas y filas. La tecnología de bases de datos relacionales
proporciona la forma más eficiente y flexible de acceder a esta
información.
Bases de datos orientadas a objetos
La información de una base de datos orientada a
objetos se representa en forma de objetos, como en la programación
orientada a objetos.
Bases de datos distribuidas
Una base de datos distribuida consta de dos o
más archivos que se encuentran en sitios diferentes. La base de
datos puede almacenarse en varios ordenadores, ubicarse en la
misma ubicación física o repartirse en diferentes redes.
Almacenes de datos
Un repositorio central de datos, un data warehouse es un tipo de
base de datos diseñado específicamente para consultas y análisis
rápidos.
Bases de datos NoSQL
Una base de datos NoSQL, o base de datos no
relacional, permite almacenar y manipular datos no estructurados y
semiestructurados (a diferencia de una base de datos relacional,
que define cómo se deben componer todos los datos insertados en la
base de datos). Las bases de datos NoSQL se hicieron populares a
medida que las aplicaciones web se volvían más comunes y
complejas.
Bases de datos orientadas a grafos
Una base de datos orientada a grafos almacena
datos relacionados con entidades y las relaciones entre entidades.
Bases de datos OLTP. Una base de datos OLTP es una base de datos
rápida y analítica diseñada para que muchos usuarios realicen un
gran número de transacciones.
Estos son solo algunos de las varias docenas de
tipos de bases de datos que se utilizan hoy en día. Otras bases de
datos menos comunes se adaptan a funciones científicas,
financieras o de otro tipo muy específicas. Además de los
diferentes tipos de bases de datos, los cambios en los enfoques de
desarrollo tecnológico y los avances considerables, como la nube y
la automatización, están impulsando a las bases de datos en
direcciones completamente nuevas. Algunas de las bases de datos
más recientes incluyen
Bases de datos de código abierto
Un sistema de base de datos de código abierto es
aquel cuyo código fuente es de código abierto; tales bases de
datos pueden ser bases de datos SQL o NoSQL.
Bases de datos en la nube
Una base de datos en la nube es una recopilación
de datos, estructurados o no estructurados, que reside en una
plataforma de cloud computing privada, pública o híbrida. Existen
dos tipos de modelos de bases de datos en la nube: el modelo
tradicional y el de base de datos como servicios (database as a
service, DBaaS). Con DBaaS, un proveedor de servicios realiza las
tareas administrativas y el mantenimiento.
Base de datos multimodelo
Las bases de datos multimodelo combinan distintos tipos de
modelos de bases de datos en un único servidor integrado. Esto
significa que pueden incorporar diferentes tipos de datos.
Bases de datos de documentos/JSON
Diseñadas para almacenar, recuperar y gestionar
información orientada a los documentos, las bases de datos de
documentos son una forma moderna de almacenar los datos en formato
JSON en lugar de hacerlo en filas y columnas.
Bases de datos de autogestión
El tipo de base de datos más nuevo e innovador,
las bases de datos de autogestión (también conocidas como bases de
datos autónomas) están basadas en la nube y utilizan el machine
learning para automatizar el ajuste de la base de datos, la
seguridad, las copias de seguridad, las actualizaciones y otras
tareas de gestión rutinarias que tradicionalmente realizan los
administradores de bases de datos.
Realiza el siguiente Test 2 Unidad 1
Tipos de
Datos (2)
Los tipos de datos que puede haber en un campo, se pueden
agrupar en tres grandes grupos:
Tipos numéricos
Tipos de Fecha
Tipos de Cadena
1 Tipos numéricos:
Existen tipos de datos numéricos, que se pueden
dividir en dos grandes grupos, los que están en coma flotante (con
decimales) y los que no.
TinyInt:
Es un número entero con o sin signo. Con signo el rango de valores
válidos va desde -128 a 127. Sin signo, el rango de valores es de
0 a 255
Bit ó Bool:
Un número entero que puede ser 0 ó 1
SmallInt:
Número entero con o sin signo. Con signo el rango de valores va
desde -32,768 a 32,767. Sin signo, el rango de valores es de 0 a
65,535.
MediumInt:
Número entero con o sin signo. Con signo el rango de valores va
desde -8,388,608 a 8,388,607. Sin signo el rango va desde 0 a
16,777,215.
Integer, Int:
Número entero con o sin signo. Con signo el rango de valores va
desde -2,147,483,648 a 2,147,483,647. Sin signo el rango va desde
0 a 4,294,967,295
BigInt:
Número entero con o sin signo. Con signo el rango de valores va
desde -9,223,372,036,854,775,808 a 9,223,372,036,854,775,807. Sin
signo el rango va desde 0 a 18,446,744,073,709,551,615.
Float:
Número pequeño en coma flotante de precisión simple. Los valores
válidos van desde -3.402823466E+38 a -1.175494351E-38, 0 y desde
1.175494351E-38 a 3.402823466E+38.
xReal, Double:
Número en coma flotante de precisión doble. Los valores permitidos
van desde -1.7976931348623157E+308 a -2.2250738585072014E-308, 0 y
desde 2.2250738585072014E-308 a 1.7976931348623157E+308
Decimal, Dec, Numeric:
Número en coma flotante desempaquetado. El número se almacena
como una cadena
Tipo de Campo
|
Tamaño de Almacenamiento |
TINYINT
|
1 byte
|
SMALLINT
|
2 byte
|
MEDIUMINT
|
3 byte
|
INT
|
4 bytes
|
INTEGER
|
4 bytes
|
BIGINT
|
8 bytes
|
FLOAT(X)
|
4 ú 8 bytes
|
FLOAT
|
4 bytes
|
DOUBLE
|
8 bytes
|
DOUBLE PRECISION
|
8 bytes
|
REAL
|
8 bytes
|
DECIMAL(M,D)
|
M+2 bytes sí D > 0,
M+1 bytes sí D = 0
|
NUMERIC(M,D)
|
M+2 bytes if D > 0,
M+1 bytes if D = 0
|
Realiza el siguiente Test 3 Unidad 1
2 Tipos fecha:
A la hora de almacenar fechas, hay que tener en
cuenta que Mysql no comprueba de una manera estricta si una fecha
es válida o no. Simplemente comprueba que el mes esta comprendido
entre 0 y 12 y que el día esta comprendido entre 0 y 31.
Date:
Tipo fecha, almacena una fecha. El rango de valores va desde el 1
de enero del 1001 al 31 de diciembre de 9999. El formato de
almacenamiento es de año-mes-dia
DateTime:
Combinación de fecha y hora. El rango de valores va desde el 1 de
enero del 1001 a las 0 horas, 0 minutos y 0 segundos al 31 de
diciembre del 9999 a las 23 horas, 59 minutos y 59 segundos. El
formato de almacenamiento es de año-mes-dia horas:minutos:segundos
TimeStamp:
Combinación de fecha y hora. El rango va desde el 1 de enero de
1970 al año 2037. El formato de almacenamiento depende del tamaño
del campo:
Tamaño
|
Formato
|
14
|
AñoMesDiaHoraMinutoSegundo
aaaammddhhmmss
|
12
|
AñoMesDiaHoraMinutoSegundo
aammddhhmmss
|
8
|
AñoMesDia
aaaammdd
|
6
|
AñoMesDia
aammdd
|
4
|
AñoMes
aamm
|
2
|
Año
aa
|
Time:
Almacena una hora. El rango de horas va desde
-838 horas, 59 minutos y 59 segundos a 838, 59 minutos y 59
segundos. El formato de almacenamiento es de 'HH:MM:SS'
Year:
Almacena un año. El rango de valores permitidos
va desde el año 1901 al año 2155. El campo puede tener tamaño dos
o tamaño 4 dependiendo de si queremos almacenar el año con dos o
cuatro dígitos.
| Tipo de Campo |
Tamaño de Almacenamiento |
| DATE |
3 bytes |
| DATETIME |
8 bytes |
| TIMESTAMP |
4 bytes |
| TIME |
3 bytes |
| YEAR |
1 byte |
Realiza el siguiente Test 4 Unidad 1
3 Tipos de cadena:
Char(n):
Almacena una cadena de longitud fija. La cadena podrá contener
desde 0 a 255 caracteres.
Comencemos por el tipo de dato alfanumérico mas
simple: CHAR (character, o carácter). (3)
Este tipo de dato permite almacenar textos breves, de hasta 255
caracteres de longitud como máximo en caracteres que le definamos,
aunque no lo utilicemos.
Por ejemplo, si definiéramos un campo "nombre"
de 14 caracteres como CHAR, reservará (y consumirá en disco) este
espacio.
1 2 3
4 5 6
7 8 9
10 11 12
13 14
J u a
n
P e r
e z
C a r
l o s
G a
r c i
a
J o s
e
R a m
i r e
z
L u i
s F
e r n a
n d e
z
P e p
e
L o p
e z
Por lo tanto, no es eficiente cuando la longitud
del dato que se almacenará en un campo es desconocida a priori
(típicamente, datos ingresados por el usuario en un formulario,
como su nombre, domicilio, etc.)
¿En qué casos usarlo, entonces? Cuando el contenido de ese campo
será completado por nosotros, programadores, al agregarse un
registro y, por lo tanto, estamos seguros de que la longitud
siempre será la misma.
VarChar(n):
Almacena una cadena de longitud variable. La cadena podrá
contener desde 0 a 255 caracteres. (3)
Complementario, el tipo de dato VARCHAR (varying
character, o caracteres variables) es útil cuando la longitud del
dato es desconocida, cuando depende de la información que el
usuario escribe en campos o áreas de texto de un formulario.
La longitud máxima permitida era de 255 caracteres hasta MySQL
5.0.3. pero desde esta versión cambio a un máximo de 65.535
caracteres.
Este tipo de dato tiene la particularidad de que cada registro
puede tener una longitud diferente, que dependerá de su contenido;
si en su registro el campo "nombre" (supongamos que hubiera sido
definido con un ancho máximo de 20 caracteres) contiene solamente
el texto: "Pepe", consumirá sólo cinco caracteres, cuatro para las
cuatro letras, y uno más que indicará cuántas letras se
utilizaron.
Si luego, en otro registro, se ingresa un nombre de 15 caracteres,
consumirá 16 caracteres (siempre uno más que la longitud del
texto, mientras la longitud no supere los 255 caracteres; si no
los supera, serán dos los bytes necesarios para indicar la
longitud).
Por lo tanto, será más eficiente para almacenar registros
cuyos valores tengan longitudes variables, ya que si bien
"gasta" uno o dos caracteres por registro para declarar la
longitud, esto le permite ahorrar muchos otros caracteres que
no serían utilizados.
Dentro de los tipos de cadena se pueden distinguir otros dos
subtipos, los tipo Test y los tipo BLOB (Binary Large Object)
La diferencia entre un tipo y otro es el
tratamiento que reciben a la hora de realizar ordenamientos y
comparaciones. Mientras que el tipo test se ordena sin tener en
cuenta las Mayúsculas y las minúsculas, el tipo BLOB se ordena
teniéndolas en cuenta.
Los tipos BLOB se utilizan para almacenar datos binarios como
pueden ser ficheros.
TinyText y TinyBlob:
Columna con una longitud máxima de 255 caracteres.
Blob y Text:
Un texto con un máximo de 65535 caracteres.
La principal desventaja de TEXT es que no puede
indexarse fácilmente (a diferencia de VARCHAR).
Tampoco se le puede asignar un valor predeterminado a un campo
TEXT (un valor por omisión que se complete automáticamente si no
se ha proporcionado un valor al insertar un registro).
Sólo deberíamos utilizarlo para textos realmente muy largos
MediumBlob y MediumText:
Un texto con un máximo de 16.777.215 caracteres.
LongBlob y LongText:
Un texto con un máximo de caracteres 4.294.967.295. Hay que
tener en cuenta que debido a los protocolos de comunicación los
paquetes pueden tener un máximo de 16 Mb.
Enum:
Campo que puede tener un único valor de una lista que se
especifica. El tipo Enum acepta hasta 65535 valores distintos.
Su nombre es la abreviatura de "enumeración".
Este campo nos permite establecer cuáles serán los valores
posibles que se le podrán insertar.
Es decir, crearemos una lista de valores
permitidos, y no se autorizará el ingreso de ningún valor fuera de
la lista, y se permitirá elegir solo uno de estos datos como valor
del campo.
Los valores deben estar separados por comas y
envueltos entre comillas simples.
El máximo de valores diferentes es de 65.535.
Lo que se almacenará no es la cadena de
caracteres en sí, sino el número de índice de su posición dentro
de la enumeración.
Set:
Un campo que puede contener ninguno, uno ó varios valores de una
lista. La lista puede tener un máximo de 64 valores.
Su nombre significa "conjunto". De la misma
manera que ENUM, debemos especificar una lista, pero de hasta 64
opciones solamente.
La carga de esos valores es idéntica a la de
ENUM, una lista de valores entre comillas simples, separados por
comas. Pero, a diferencia de ENUM, sí podemos llegar a dejarlo
vacío, sin elegir ninguna opción de las posibles.
Y también podemos elegir como valor del campo
más de uno de los valores de la lista.
Por ejemplo, darnos a elegir una serie de temas
(típicamente con casillas de verificación que permiten selección
múltiple) y luego almacenamos en un solo campo todas las opciones
elegidas.
Un detalle importante es que cada valor dentro
de la cadena de caracteres no puede contener comas, ya que es la
coma el separador entre un valor y otro.
| Tipo de campo |
Tamaño de Almacenamiento |
| CHAR(n) |
n bytes |
| VARCHAR(n) |
n +1 bytes |
| TINYBLOB, TINYTEXT |
Longitud+1 bytes |
| BLOB, TEXT |
Longitud +2 bytes |
| MEDIUMBLOB, MEDIUMTEXT |
Longitud +3 bytes |
| LONGBLOB, LONGTEXT |
Longitud +4 bytes |
| ENUM('value1','value2',...) |
1 ó dos bytes dependiendo del número de
valores |
| SET('value1','value2',...) |
1, 2, 3, 4 ó 8 bytes, dependiendo del número
de valores |
Diferencia de almacenamiento entre los tipos Char y VarChar
| Valor |
CHAR(4) |
Almacenamiento |
VARCHAR(4) |
Almacenamiento |
| '' |
'' |
4 bytes |
" |
1 byte |
| 'ab' |
'ab ' |
4 bytes |
'ab' |
3 bytes |
| 'abcd' |
'abcd' |
4 bytes |
'abcd' |
|
| 'abcdefgh' |
'abcd' |
4 bytes |
'abcd' |
5 bytes |
Realiza el siguiente Test 5 Unidad 1
También
podemos incluir los atributos de los campos:
NULL (4)
El valor NULL representa a un valor desconocido.
Este valor NULL puede ser asignado como valor a cualquier columna
de una tabla.
Si el valor de una columna es opcional, quiere decir, que podemos
insertar una fila en la tabla sin asignarle ningún valor a esa
columna opcional, así que esa columna tomará el valor NULL.
El valor NULL es un valor especial, y por tanto, no se puede
comparar con los operadores aritméticos normales (=, >, <,
<>), y en su lugar debemos utilizar los operadores IS y IS
NOT.
En la tabla personas, tenemos la columna 'apellido2' que es
opcional y puede tener valores nulos:
nombre apellido1
apellido2 edad
ANTONIO PEREZ
30
LUIS
LOPEZ
PEREZ 45
ANTONIO GARCIA
50
DEFAULT (5)
La restricción DEFAULT se usa para proporcionar un valor
predeterminado para una columna.
El valor predeterminado se agregará a todos los registros nuevos
SI no se especifica ningún otro valor.
BINARY (6)
Los tipos BINARY y VARBINARY son similares a
CHAR y VARCHAR, excepto que almacenan cadenas binarias en lugar de
cadenas no binarias. Es decir, almacenan cadenas de bytes en lugar
de cadenas de caracteres. Esto significa que tienen el binary
juego de caracteres y la clasificación, y la comparación y
clasificación se basan en los valores numéricos de los bytes en
los valores.
La longitud máxima permitida es la misma para BINARY y VARBINARY
que para CHAR y VARCHAR, excepto que la longitud de BINARY y
VARBINARY se mide en bytes en lugar de caracteres.
Ejemplo: Para una BINARY(3)columna, 'a 'se
vuelve 'a \0'cuando se inserta. 'a\0'se vuelve 'a\0\0'cuando se
inserta. Ambos valores insertados permanecen sin cambios para las
recuperaciones.
Para VARBINARY, no hay relleno para inserciones y no se eliminan
bytes para recuperaciones. Todos los bytes son significativos en
las comparaciones, incluidas las operaciones ORDER BY y DISTINCT.
0x00 y el espacio difieren en las comparaciones, con 00x0 la
clasificación antes que el espacio.
INDEX (7)
MySQL emplea los índices para encontrar las
filas que contienen los valores específicos de las columnas
empleadas en la consulta de una forma más rápida. Si la
tabla contiene índices en las columnas empleadas en la consulta,
MySQL tendría una referencia directa hacia los datos sin necesidad
de recorrer secuencialmente todos ellos.
PRIMARY KEY (8)
Introducción a la clave principal de MySQL
Una clave principal es una columna o un conjunto de columnas que
identifica de forma única cada fila de la tabla. La clave primaria
sigue estas reglas:
Una clave principal debe contener valores únicos. Si la clave
principal consta de varias columnas, la combinación de valores en
estas columnas debe ser única.
Una columna de clave principal no puede tener NULL valores.
Cualquier intento de insertar o actualizar NULL las columnas de la
clave principal generará un error. Tenga en cuenta que MySQL
agrega implícitamente una NOT NULL restricción a las columnas de
clave principal.
Una tabla puede tener una y solo una clave primaria.
Debido a que MySQL funciona más rápido con
números enteros, el tipo de datos de la columna de la clave
principal debe ser el número entero, por ejemplo, y debe
asegurarse de que los rangos de valores del tipo entero para la
clave principal sean suficientes para almacenar todas las filas
posibles que pueda tener la tabla. INT, BIGINT.
Cuando define una clave principal para una
tabla, MySQL crea automáticamente un índice llamado PRIMARY.
Foreign Key FK
La clave foránea identifica una columna o grupo
de columnas en una tabla (tabla hija o referendo) que se refiere a
una columna o grupo de columnas en otra tabla (tabla maestra o
referenciada). Las columnas en la tabla referendo deben ser la
clave primaria u otra clave candidata en la tabla referenciada.
Los valores en una fila de las columnas
referendo deben existir solo en una fila en la tabla referenciada.
Así, una fila en la tabla referendo no puede contener valores que
no existen en la tabla referenciada. De esta forma, las
referencias pueden ser creadas para vincular o relacionar
información. Esto es una parte esencial de la normalización de
base de datos. Múltiples filas en la tabla referendo pueden hacer
referencia, vincularse o relacionarse a la misma fila en la tabla
referenciada. Mayormente esto se ve reflejado en una relación uno
(tabla maestra o referenciada) a muchos (tabla hija o referendo).
AUTO_INCREMENT (9)
El incremento automático permite generar
automáticamente un número único cuando se inserta un nuevo
registro en una tabla. A menudo, este es el campo de clave
principal que nos gustaría que se creara automáticamente cada vez
que se inserta un nuevo registro.
UNIQUE (10)
A veces, desea asegurarse de que los valores de
una columna o un grupo de columnas sean únicos. Por ejemplo, las
direcciones de correo electrónico de los usuarios de la users
tabla o los números de teléfono de los clientes de la customers
tabla deben ser únicos. Para hacer cumplir esta regla, utiliza una
restricción UNIQUE. Es una restricción de integridad que garantiza
que los valores de una columna o grupo de columnas sean únicos.
Una restricción UNIQUE puede ser una restricción de columna o una
restricción de tabla.
FULLTEXT (11)
La búsqueda de texto completo en el servidor
MySQL permite a los usuarios ejecutar consultas de texto completo
en datos basados en caracteres en tablas MySQL. Debe crear un
índice de texto completo en la tabla antes de ejecutar consultas
de texto completo en una tabla. El índice de texto completo puede
incluir una o más columnas basadas en caracteres en la tabla.
FULLTEXT es el tipo de índice de índice de texto completo en
MySQL.
Realiza el siguiente Test 6 Unidad 1
Diseño de
Tablas en la base de datos
Ahora que ya tenemos la información suficiente
para poder definir la forma de que se almacenaran los datos en los
campos de la tabla, procedemos al diseño de las tablas, en la base
de datos, para ello hay varias herramientas, una de ellas es
DBDesigner 4, este solo se mantuvo hasta la versión 6.9 de Centos,
en CentOS 7, ya no se actualizo, pero en Windows esta disponible,
funciona bien, para nuestro caso en CentOS stream 9/ Rocky Linux
9, usaremos esta pagina WEB que hace el mismo proceso que
DBDesigner, solo hay que registrarse, y también es funcional en
Windows se recomienda usar esta app:
1.- Iniciamos en la pagina : https://app.dbdesigner.net/
que nos llevara a lo siguiente:
2.- Del lado derecho vemos una etiqueta que tiene como nombre
Guest, hacemos clic ahí y seleccionamos Sign-up, firmarse para
tener un área de trabajo y guardar el diseño(s) de la tablas para
la base de datos.
3.- Nos solicitara algunos datos sin complicaciones de
autorizaciones u confirmaciones, al terminar de ingresar
información hacemos clic en la parte inferior CREATE ACCOUNT +
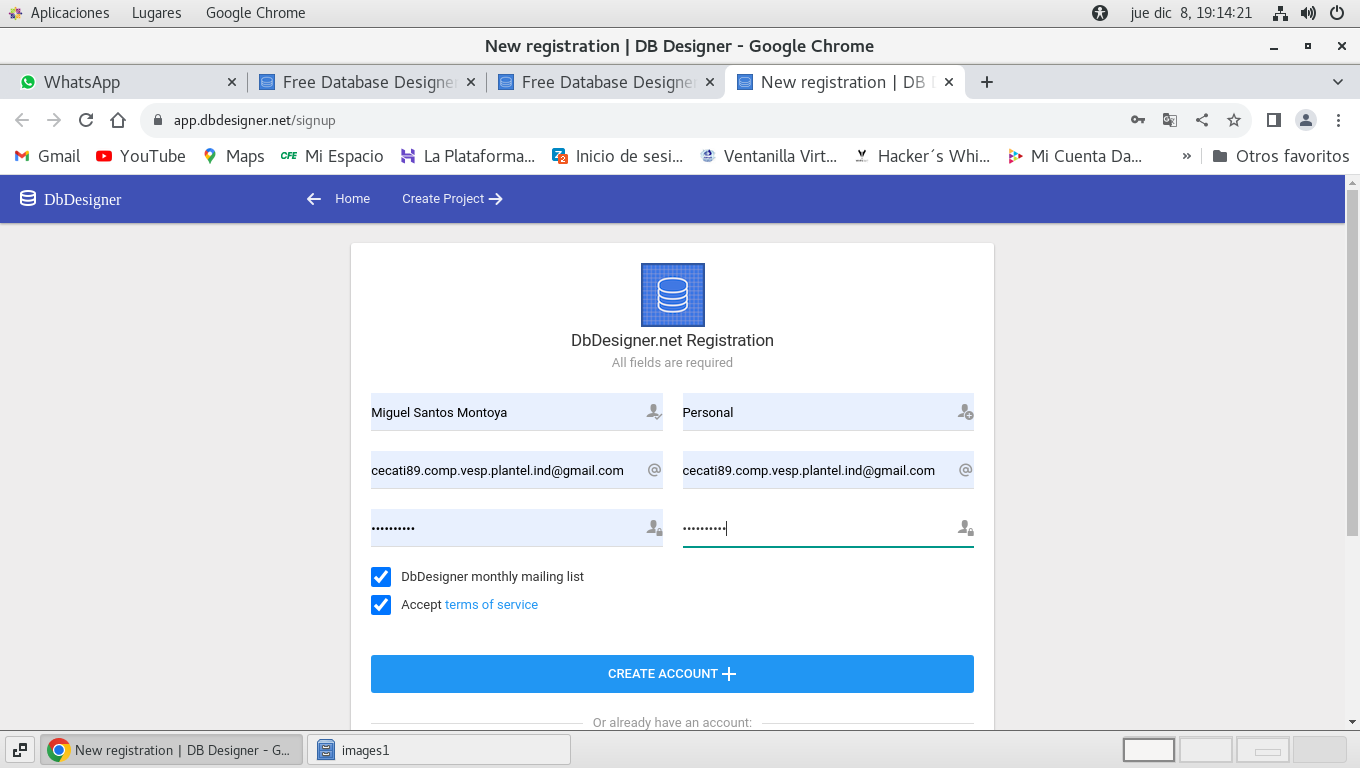
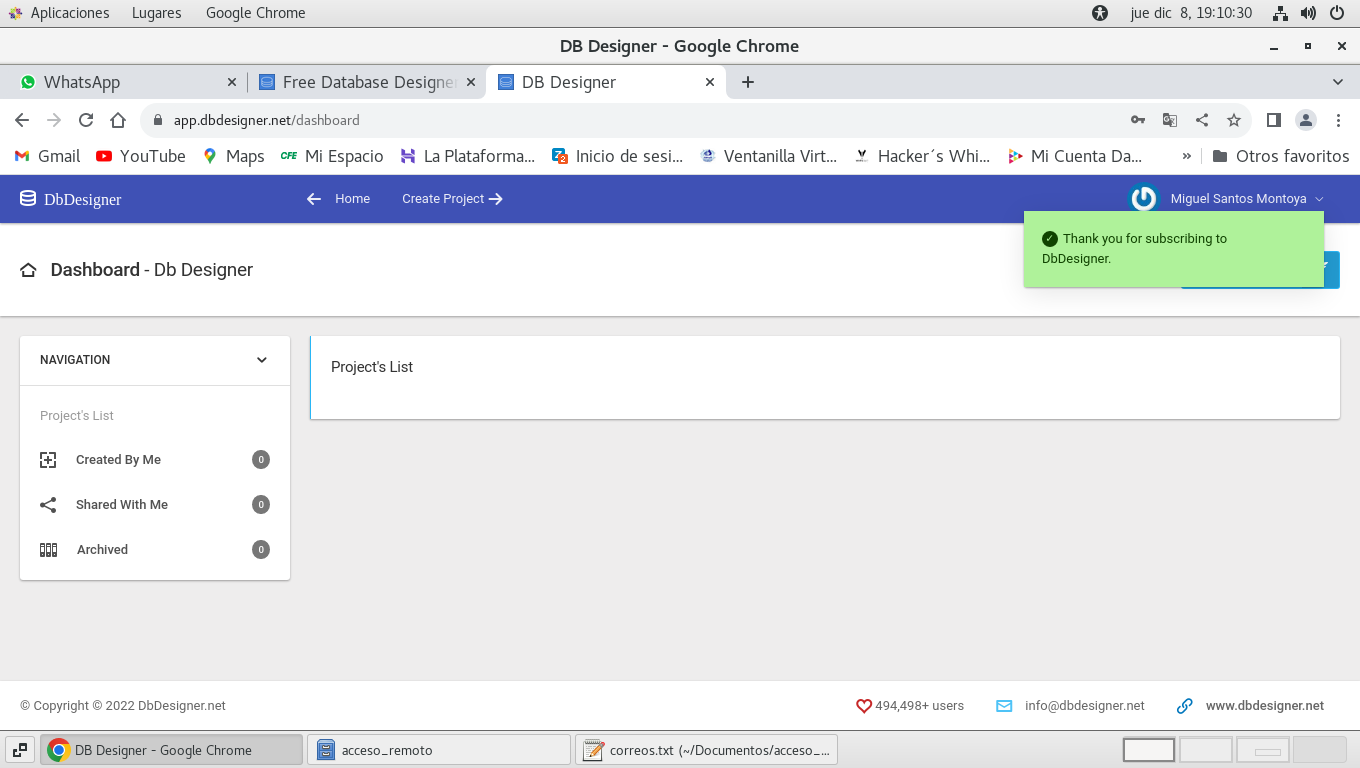
4.- Terminado el proceso de firma nos mostrara
el nombre con se firmo, y listo para realizar tablas de las bases
de datos.
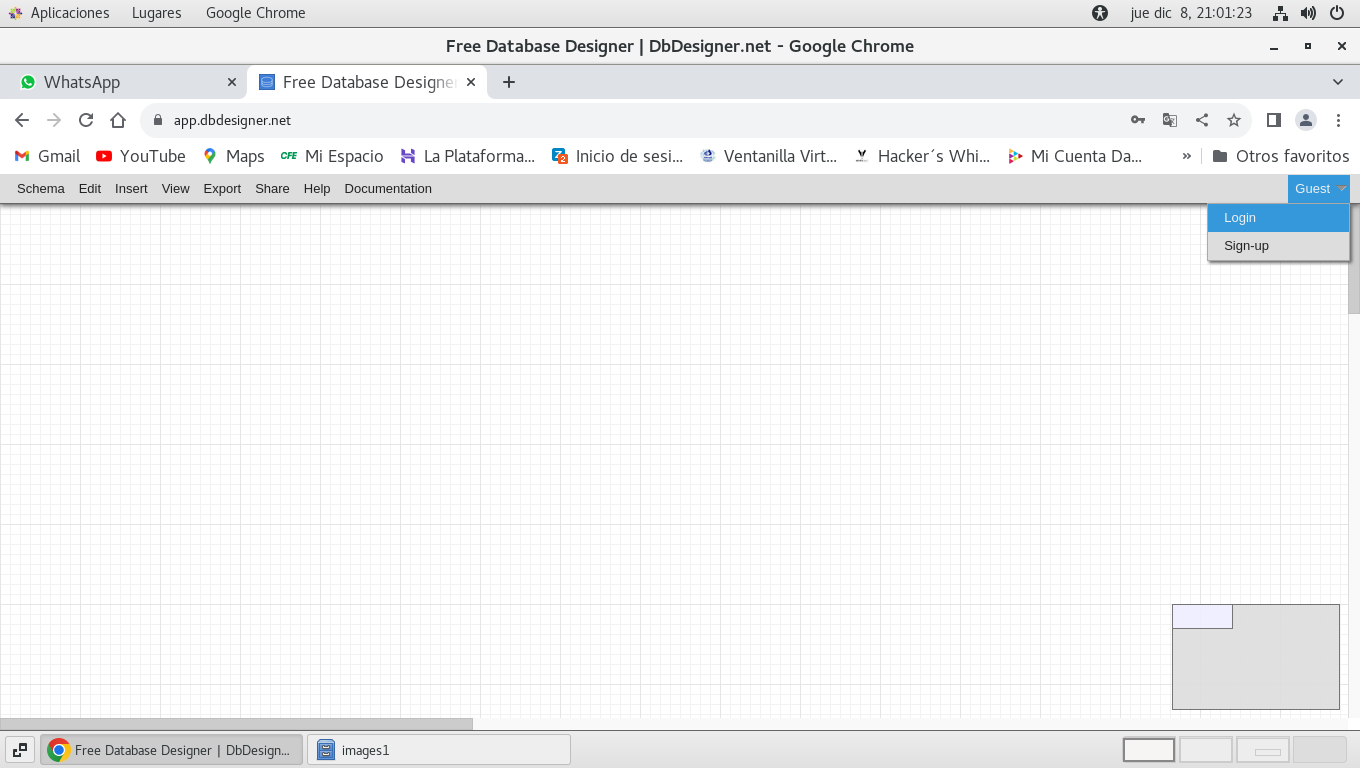
5.- Finalmente cuando requerimos acceder a muestro pizarrón,
usamos el botón Guest, y Login:
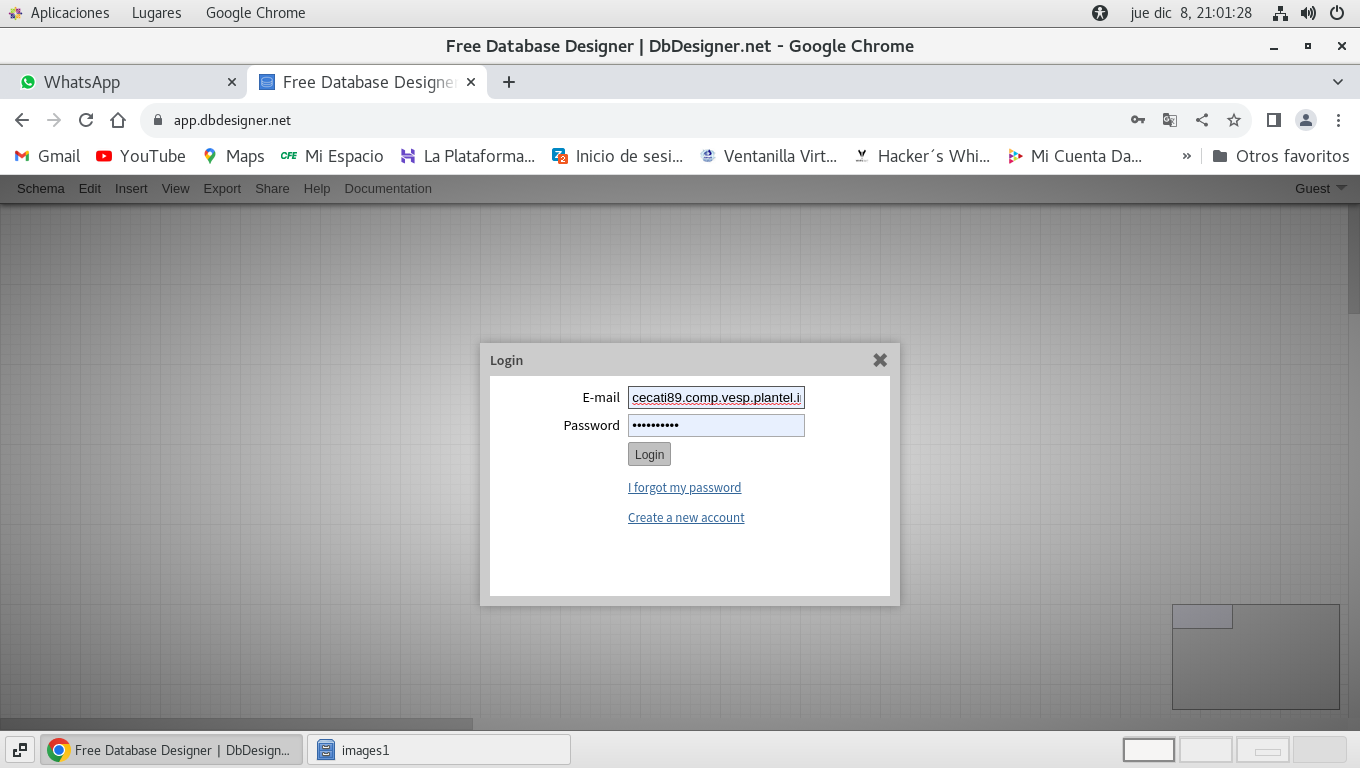
6. - Autentificamos con los datos registrados
7.- Si deseas puedes cambiar de idioma para poder trabajar con
facilidad, deberás de usar menú View -> Options...
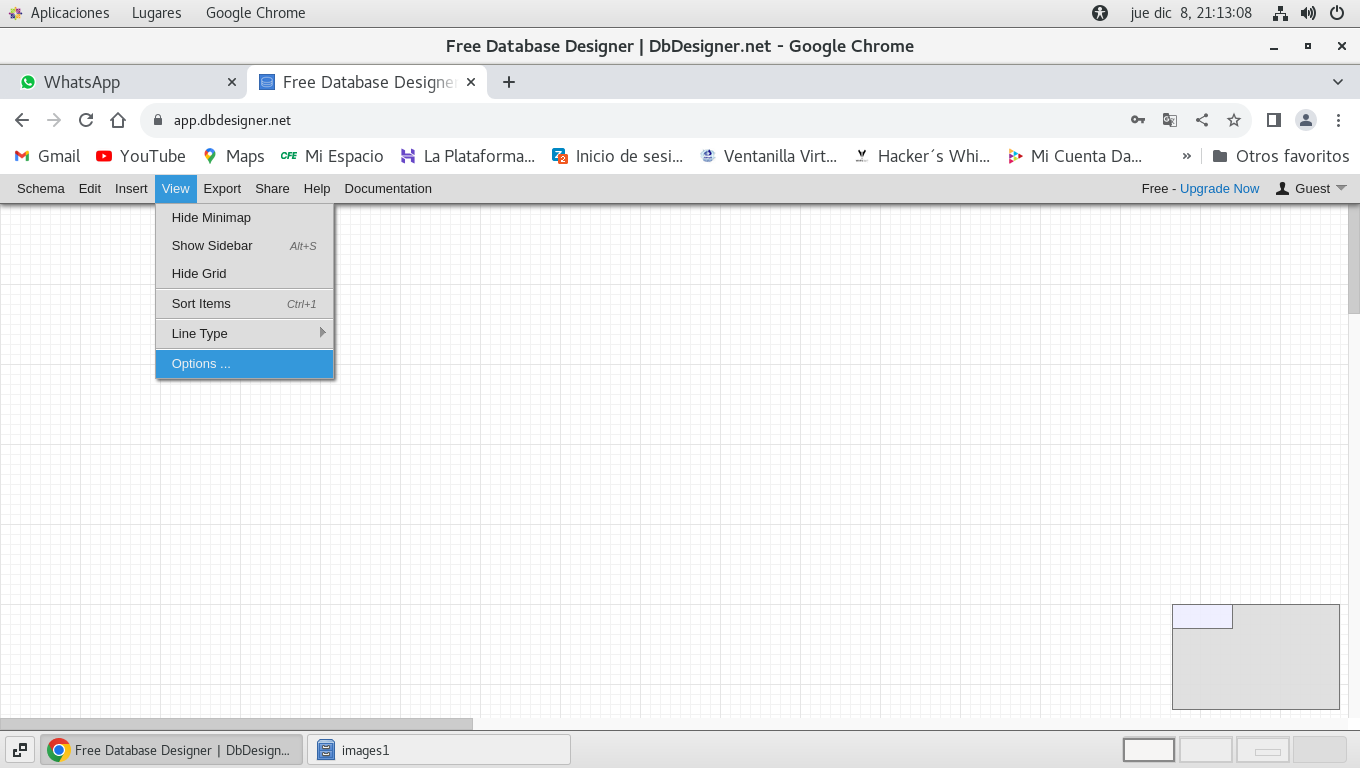
8.- Seleccionar de la lista el idioma que mas te acomode para
trabajar.
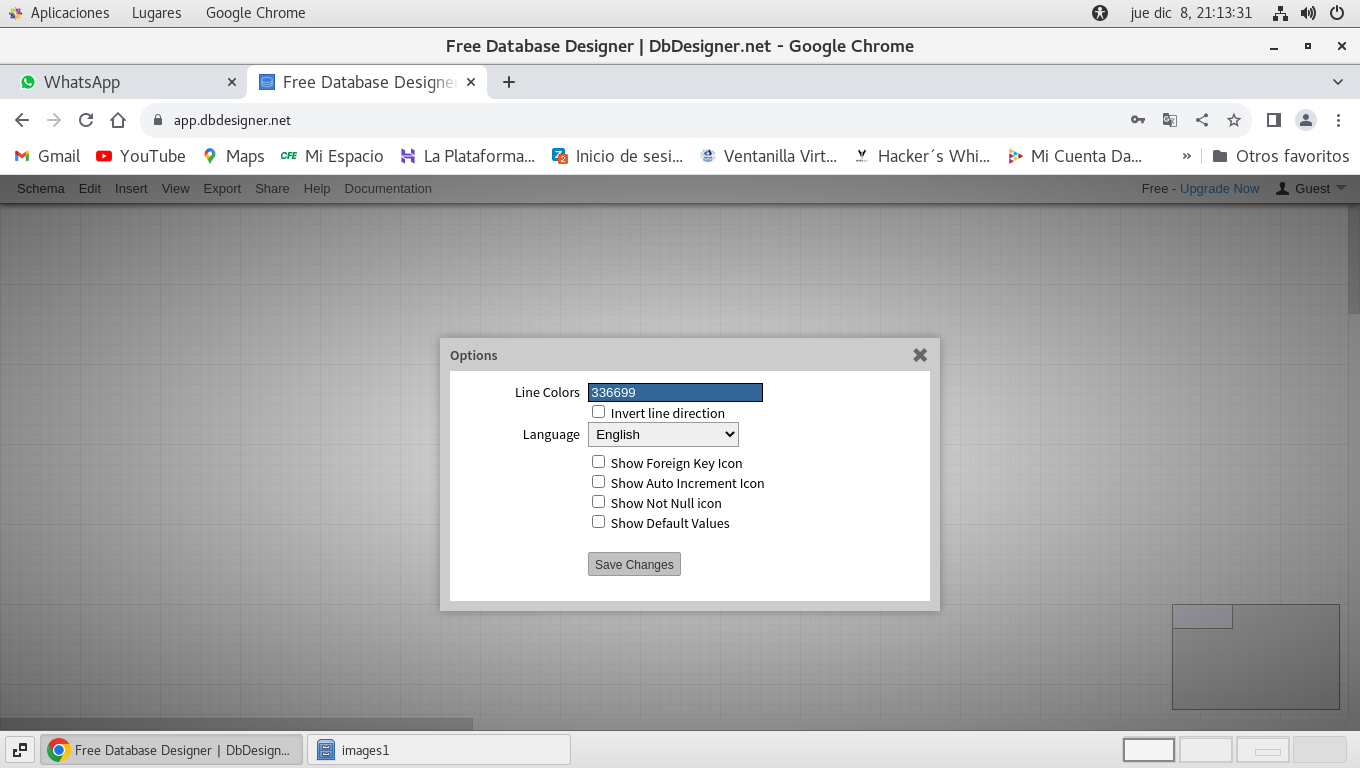
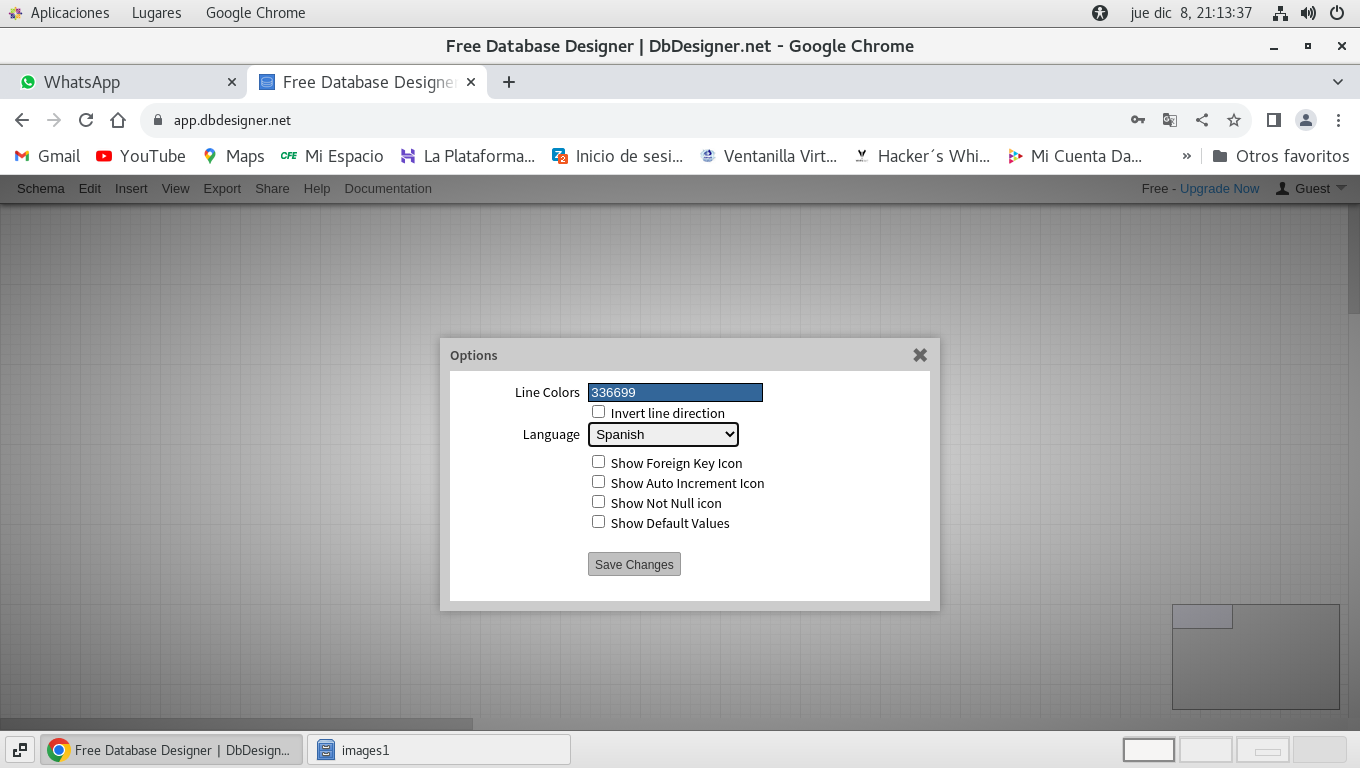
Realizado el cambio de idioma hacemos clic en Save Changes
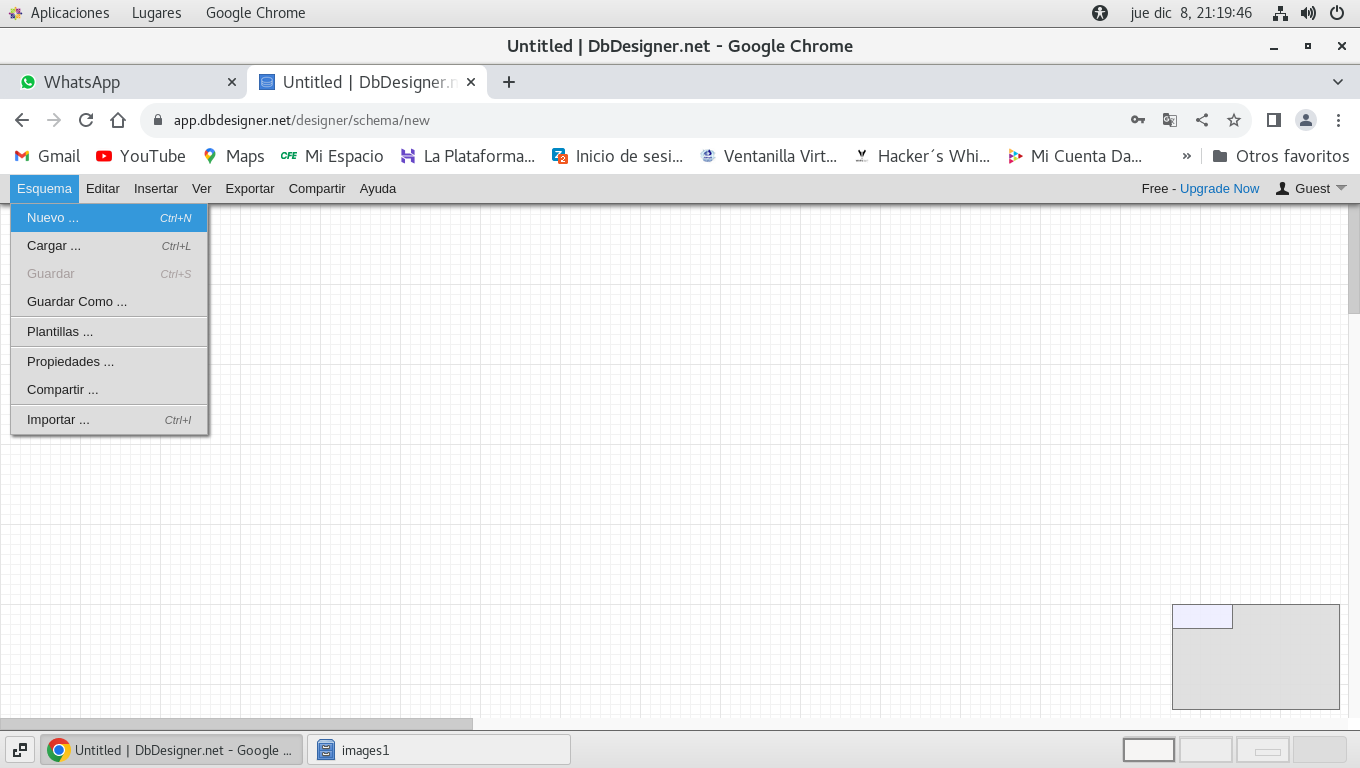
Comencemos por establecer el nombre del proyecto, desde el menú
Esquema, Nuevo ...
Seleccionamos el sistema de bases de datos que necesitemos para
realizar la estructura junto con sus tablas, en este caso Mysql, y
le establecemos un nombre por ejemplo personal.
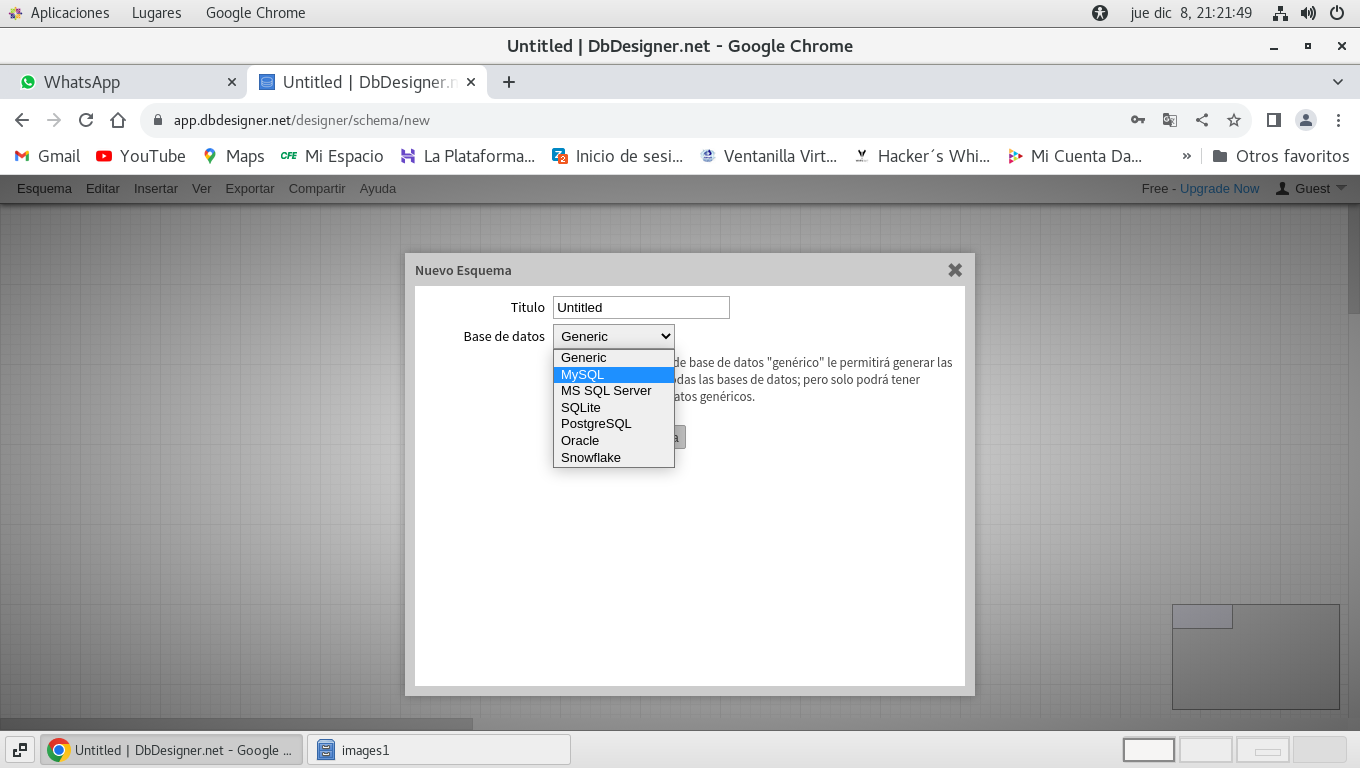
y clic en Crear nuevo esquema
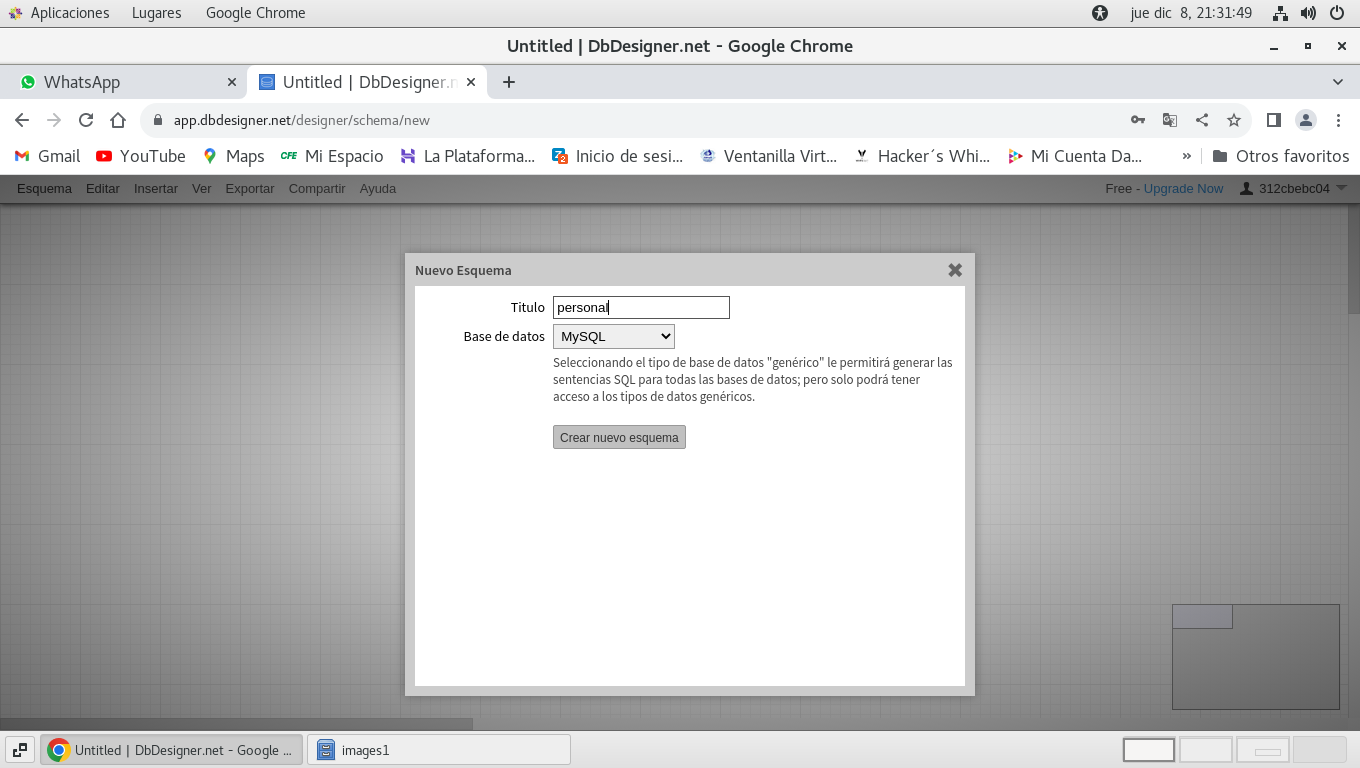
el siguiente paso es en el menú Insertar -> Tabla
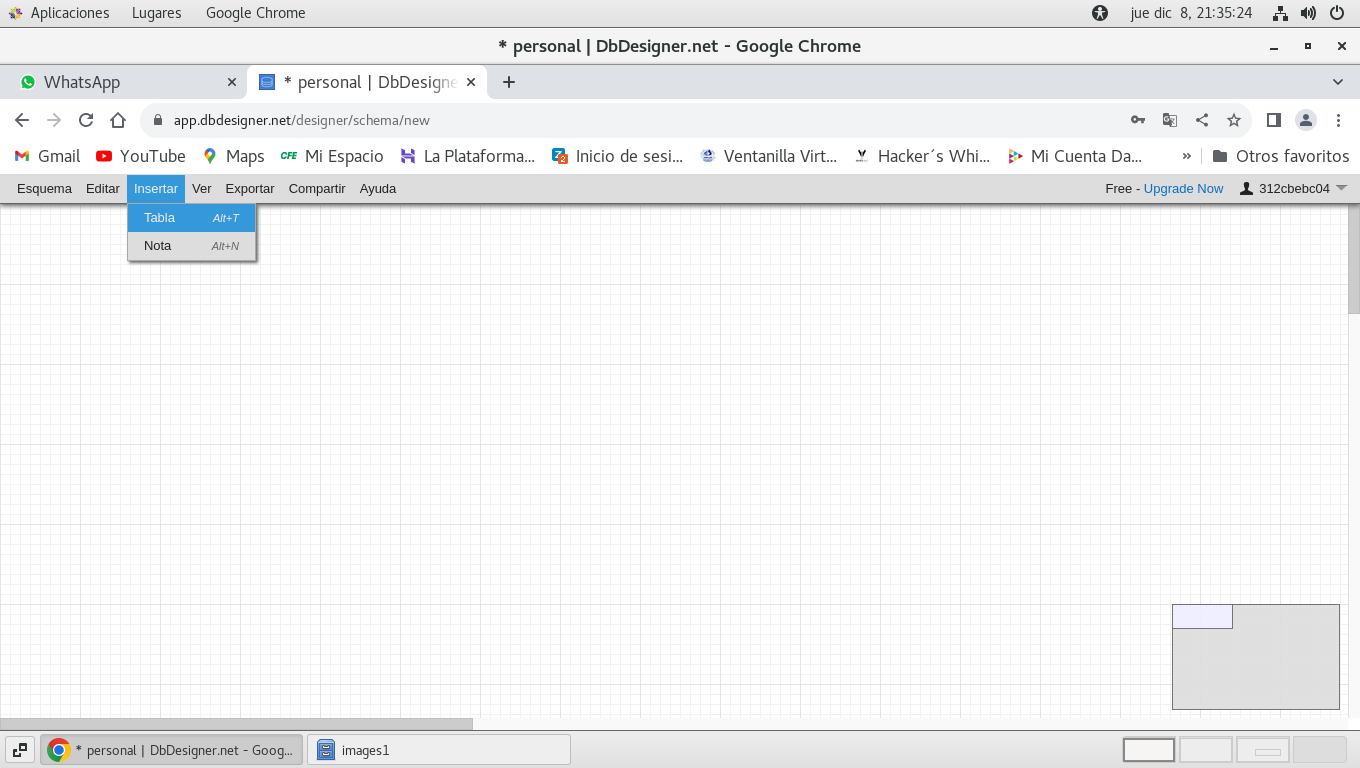
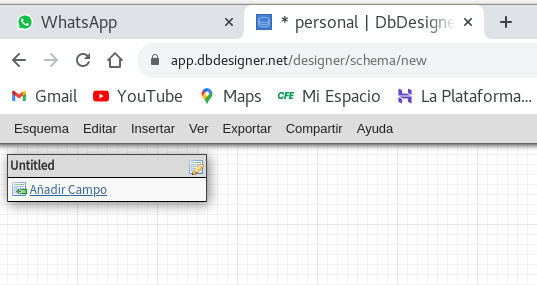
Comencemos con un ejemplo simple en la base de
datos llamada personal agregaremos una tabla de nombre
personas_informatica, (sin acentos) para cambiar el nombre,
observe la imagen anterior, en la parte superior de la tabla esta
un icono que tiene una hoja y un lápiz  hagan clic ahí y te solicitara que
coloques un nombre a la tabla:
hagan clic ahí y te solicitara que
coloques un nombre a la tabla:
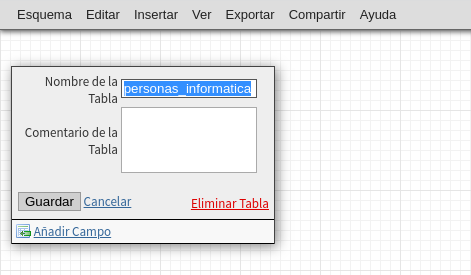
si desean agrega un comentario como, esta
tabla es la del personal que trabaja en el área de informática,
solo clic en Guardar, y posteriormente Comenzamos a añadir campos
(en la parte inferior Añadir Campo) que en esta tabla tendrán los
siguientes datos: Nombre, Apellido_p, Apellido_m, Dom_calle,
Dom_num, Tel_celular, Tel_fijo, Fecha_nac, Fecha_ingreso,
Horas_trabajo, los tipos de datos son los siguientes:
Nombre
|
varchar(20) |
Apellido_p
|
varchar(15) |
| Apellido_m |
varchar(15) |
| Dom_calle |
varchar(25) |
Dom_num
|
int |
Tel_celular
|
varchar(15) |
Tel_fijo
|
varchar(15) |
Fecha_nac
|
date |
| Fecha_ingreso |
date |
| Horas_trabajo |
int |
con estos datos se vería asi:
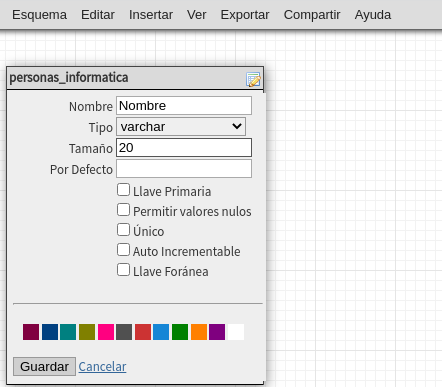
Todos los campos de esta tabla se deberán de verse asi:
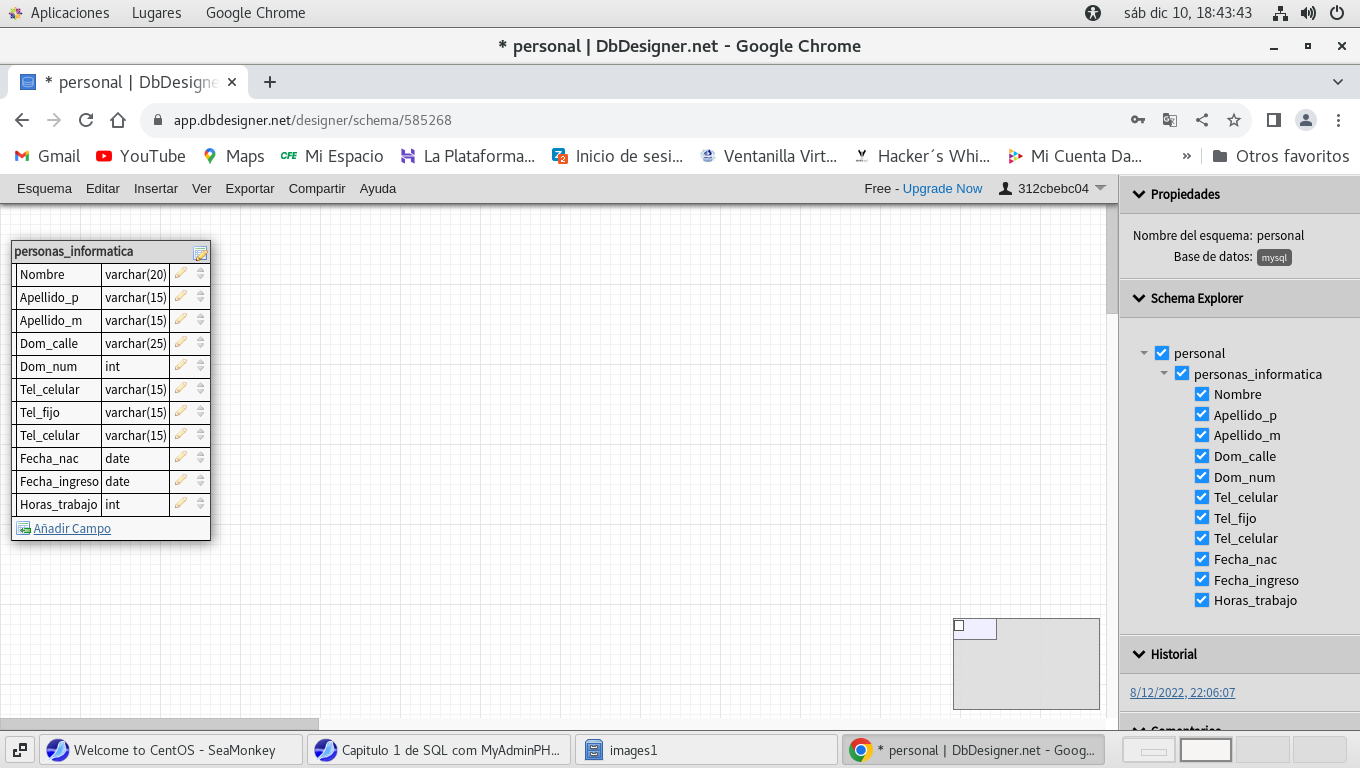
Antes de continuar debemos guardar el esquema con la tabla,
usamos el menú Esquema y Guardar como ..
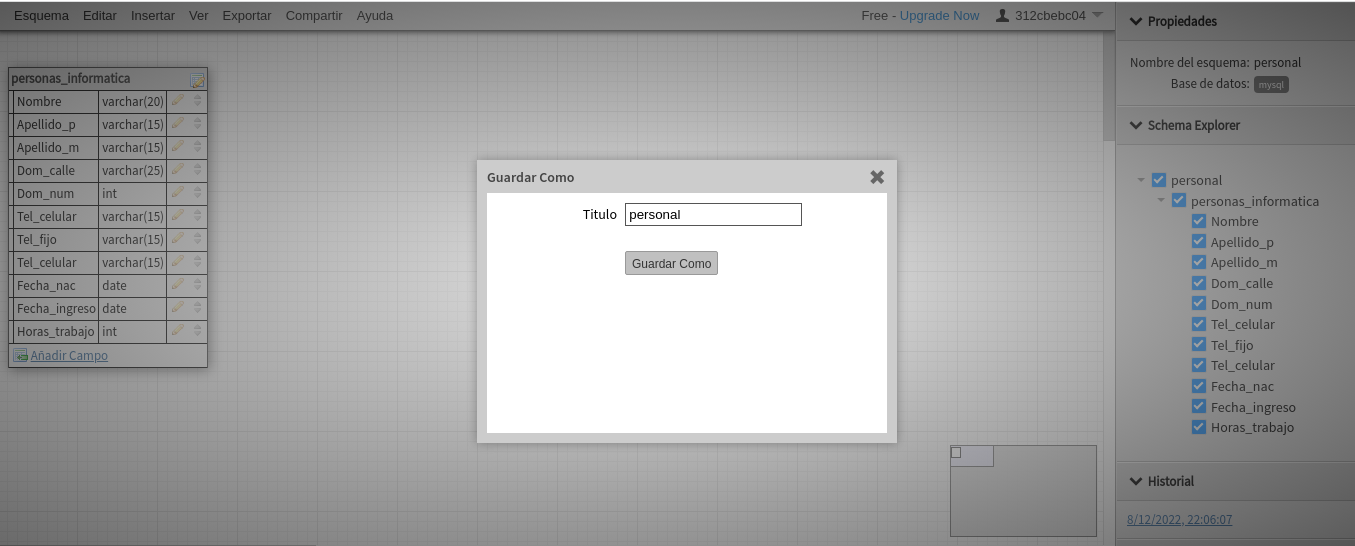
El nombre a guardar será personal que es el nombre del
esquema, y dentro del esquema esta la tabla personal_informatica
Ya tenemos nuestro primer esquema (Base de Datos) y nuestra
primer tabla. Podemos cerrar el esquema si asi fuera necesario, y
al volver a la pagina y autentificarse de nuevo para continuar:
para cerrar:
para ingresar:
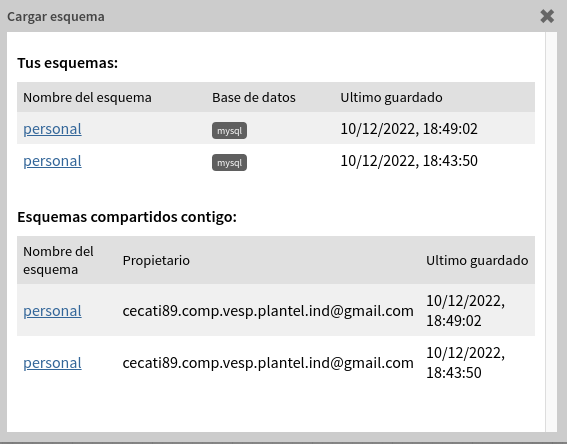
después debemos cargar el esquema que estamos
usando aquí lo guarde 2 ocasiones para que se note la forma que
podemos tener varios esquemas (Bases de Datos), tomo la primera es
el mas reciente, cuando se vaya creando mas tablas, solo tome la
opción guardar .
Cuando tengamos acceso a nuestro diseño lo
podemos exportar a un "formato" para SQL, (que lo utilizaremos
para realizar nuestra tabla en PhpMyAdmin, y agregarlo en
mariaDB), usamos el menú Exportar -> SQL).
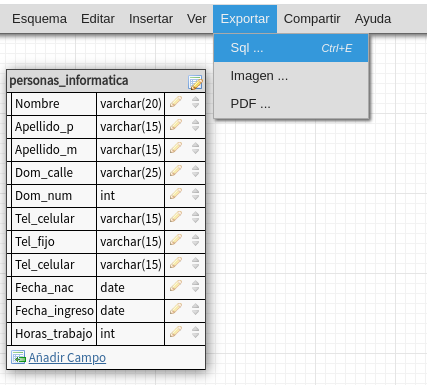
Seleccionamos Create script (genera la secuencia para la
creación de una tabla en mariaDB)
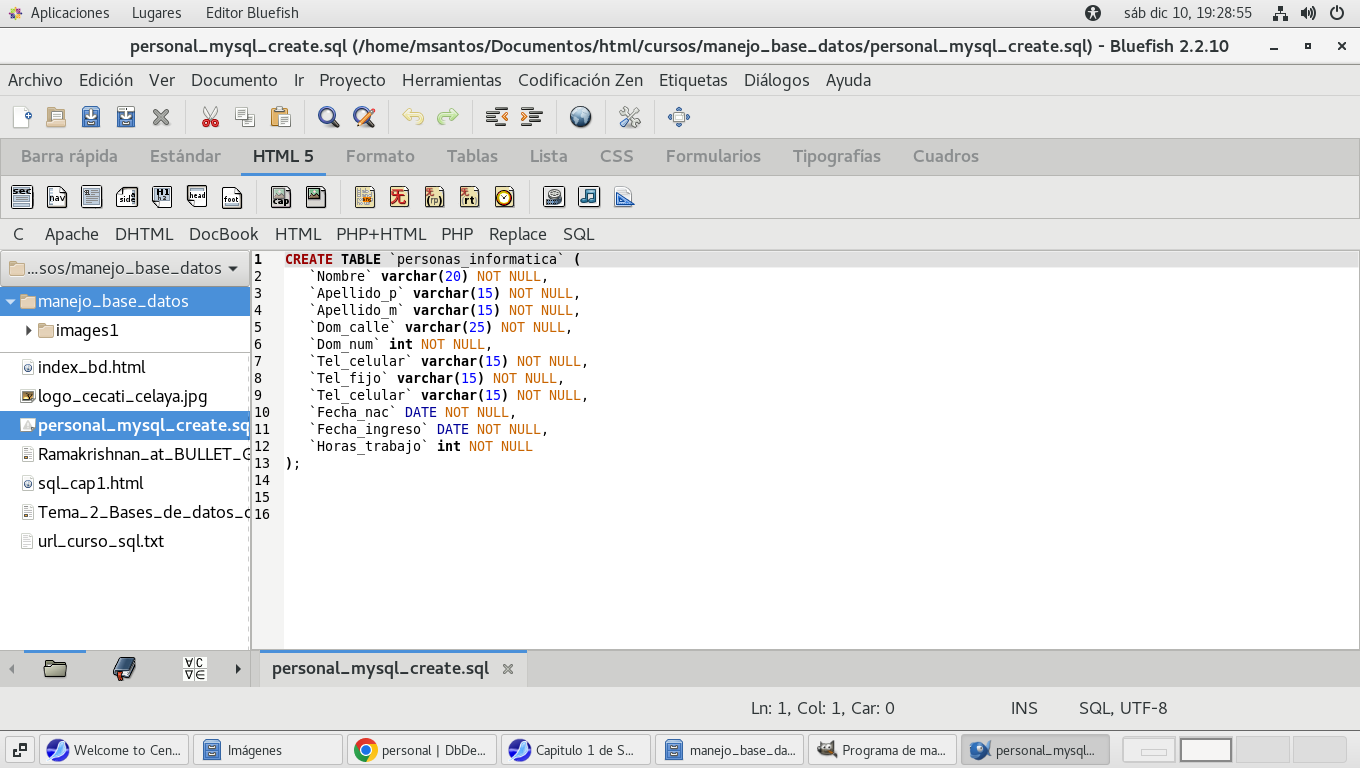
se guarda en un directorio que prefieras y al leerlo se vera asi
(puede ser con cualquier editor de texto, en nuestro caso con
Editor BlueFish, este editor esta solo en LINUX, no hay para
Windows, pero puedes usar el block de notas):
Podemos usarlo, copiando el contenido a PhpMyAdmin.
Iniciamos PhpMyAdmin, (en la unidad 1, capitulo
2 se explica como instalar MySQL y PhpMyAdmin, en Gestion de
sistemas operativos, en LINUX, que es la plataforma adecuada para
PhpMyAdmin) y creamos un esquema (base de datos) llamada personal,
del lado izquierdo el panel, haga clic en Nueva, se mostrara del
lado derecho Base de Datos, y escribimos personal, y botón crear:
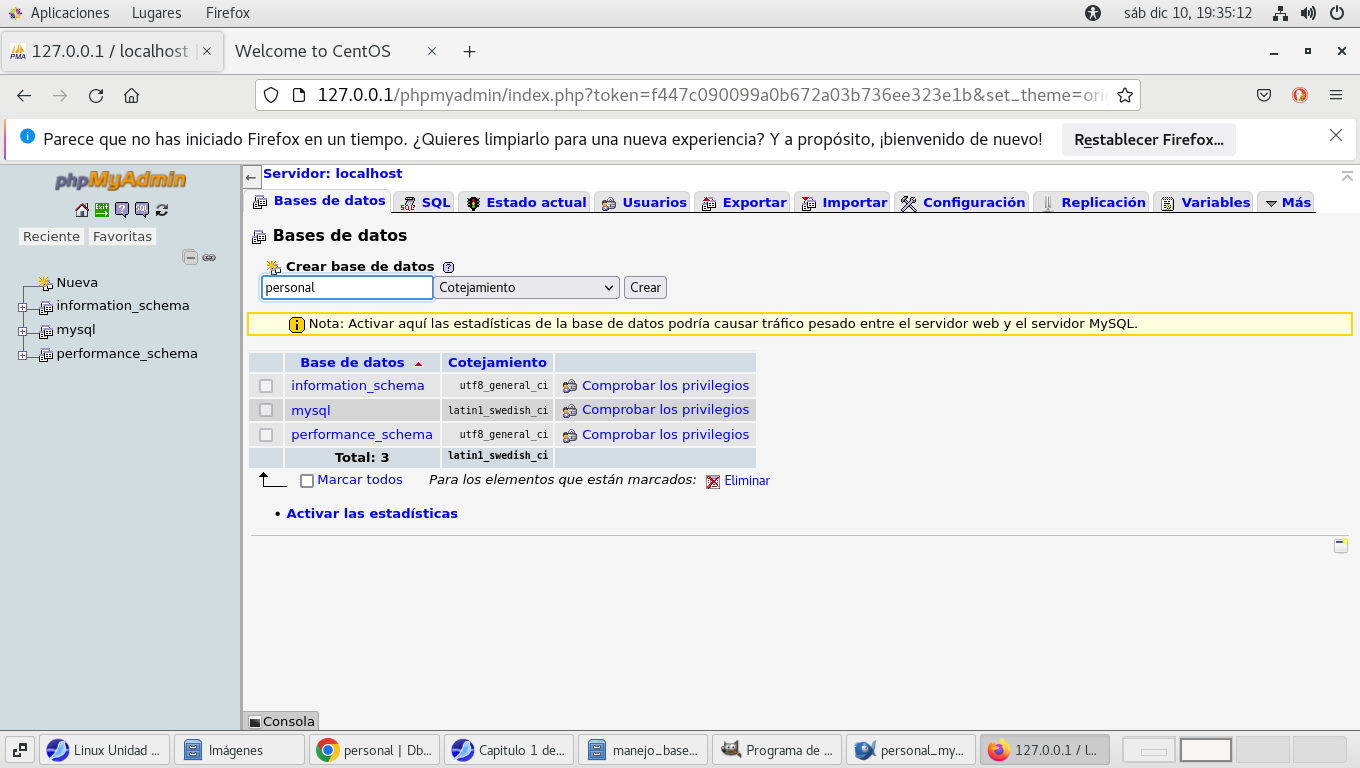
No hay tablas creadas aun, usemos la etiqueta SQL, y copiemos el
script que nos genero DBDesigner en ese lugar
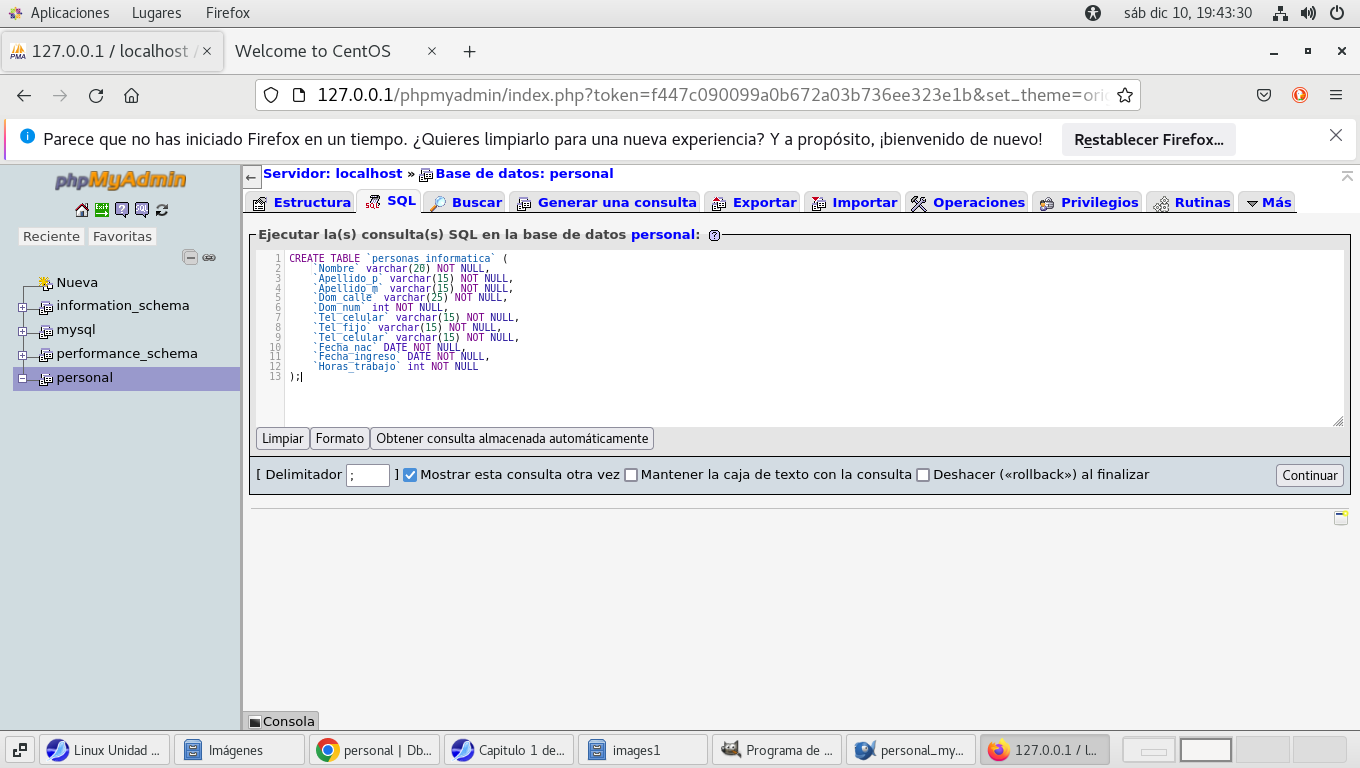
Hacemos clic en el botón continuar (si existiese un problema en
la estructura de la tabla se mostrara en la parte inferior de la
ventana)
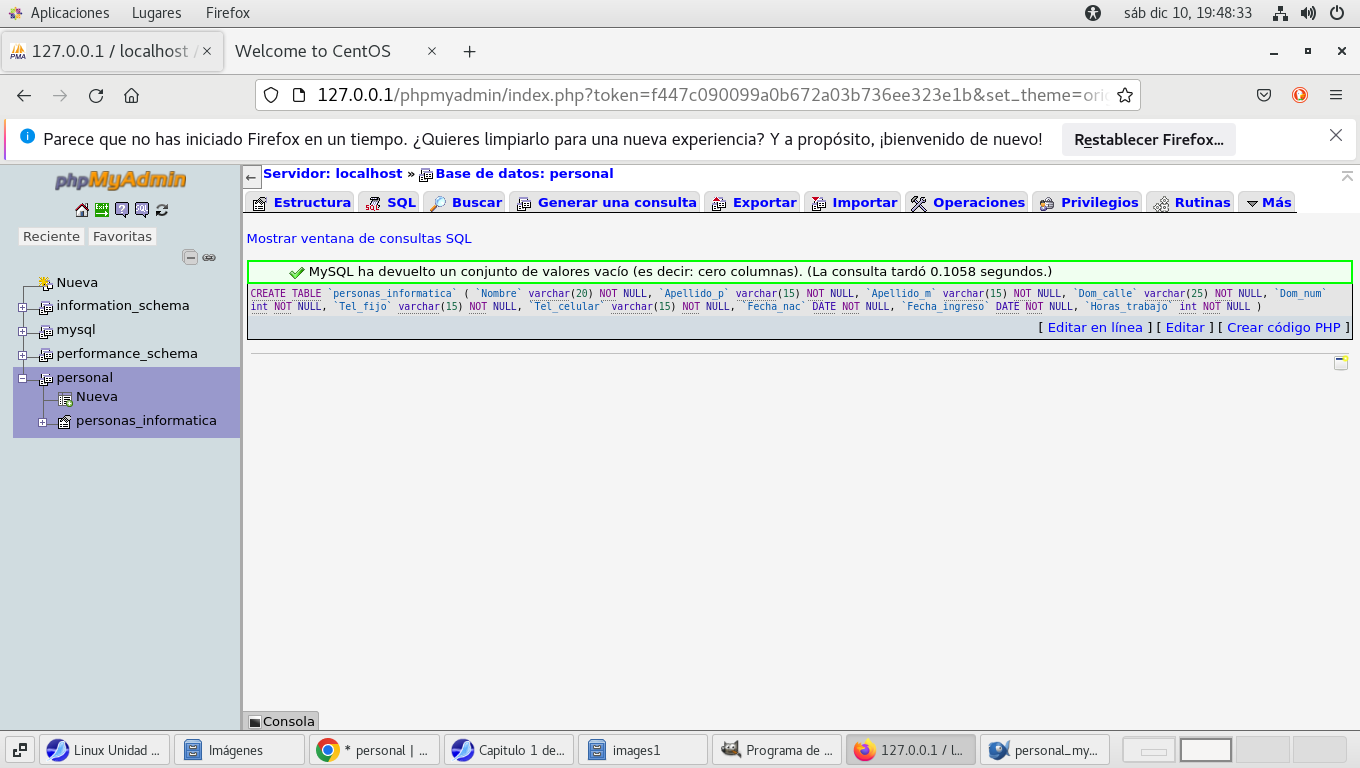
vemos que el resultado de la consulta da por resultado la
creación de una tabla llamada personas_informatica, (a pesar que
dice consulta la instrucción es CREATE TABLE, del lado
izquierdo vemos la jerarquía de la estructura, personal, es la
base de datos, y de ahí se desprende personas_informatica, el
recuadro verde indica que todo se realizo correctamente:
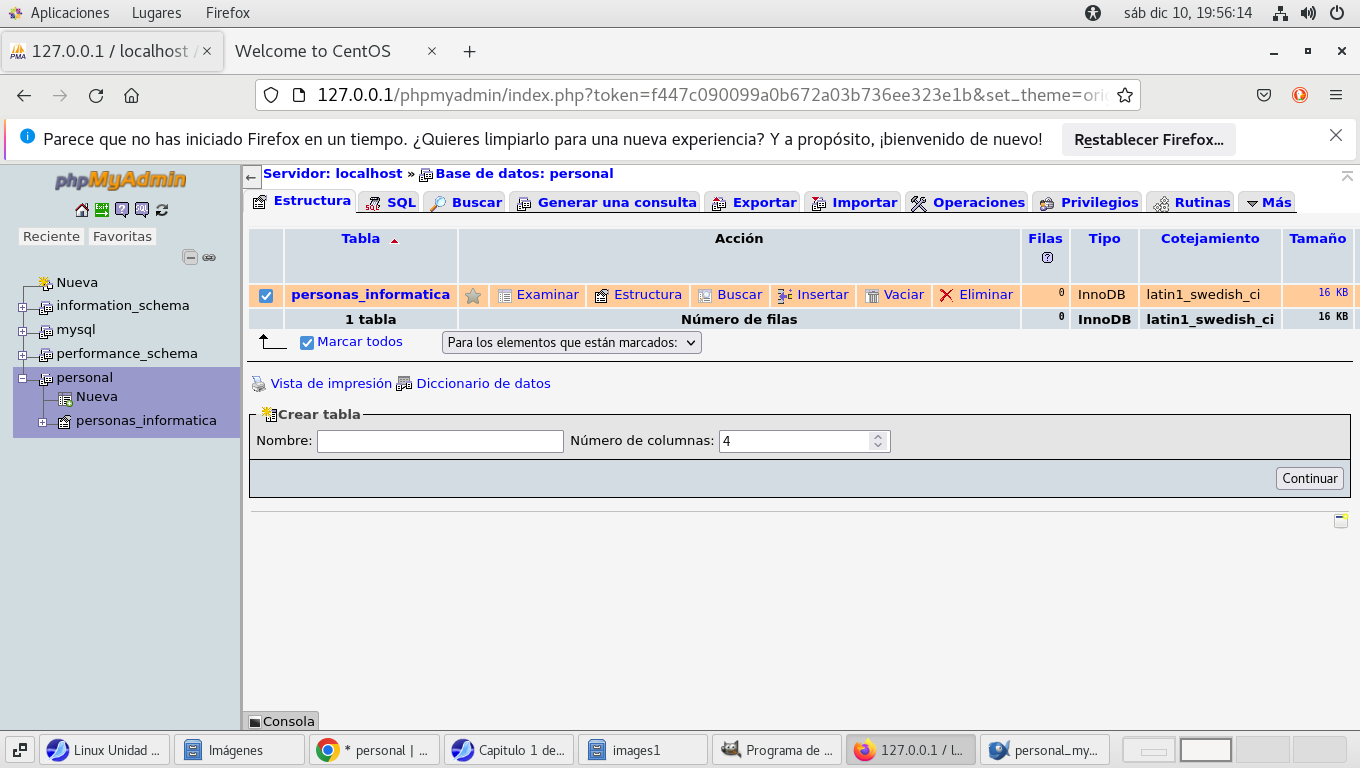
Regresemos a el separador llamado Estructura
(Schema, Esquema), y veamos lo que nos muestra, una columna que
tiene el nombre de la tabla, personas_informatica, consideren un
punto importante los tipos int definen como int(2), int(10),
significa el tamaño del campo, no el valor, lo pueden manejar sin
problema pero lo consideran como int unicamente, en windows puede
marcar un mensaje de Warning, pero no hay problema, puede
considerar campos int como de esta forma o con longitud de campo,
espara restringir la longitud de datos pero int, seguira teniendo
su capacidad de almacenamiento, recuerdas cual es su rango de
valores ?.
Hagamos clic en el botón estructura (de la tabla), y observemos
que la estructura de la tabla se encuentra lista para comenzar a
recibir datos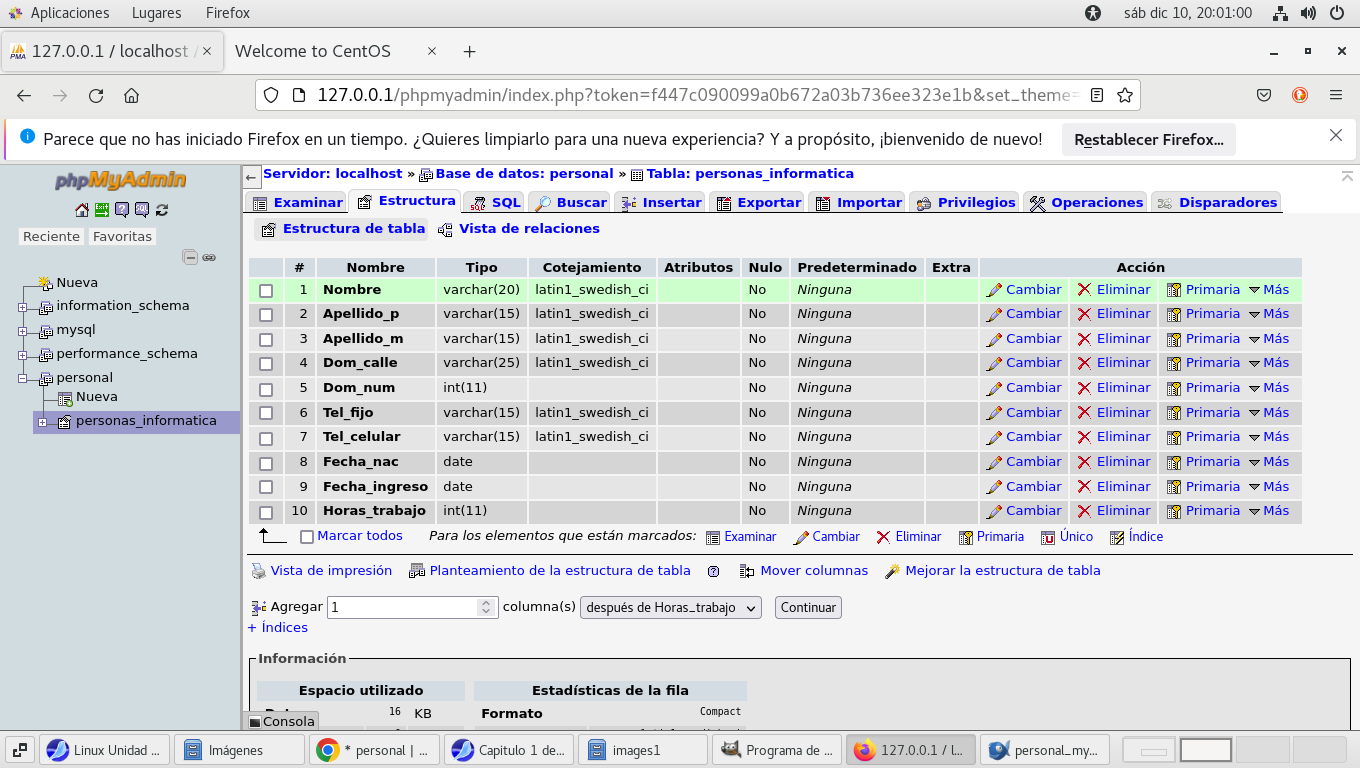
podemos agregar datos directamente, ve el titulo
en color rojo (claro es un ejemplo de como ingresar datos, pero el
proceso se hace desde una interface apropiada como una pagina web
pero aquí lo haremos de forma directa)
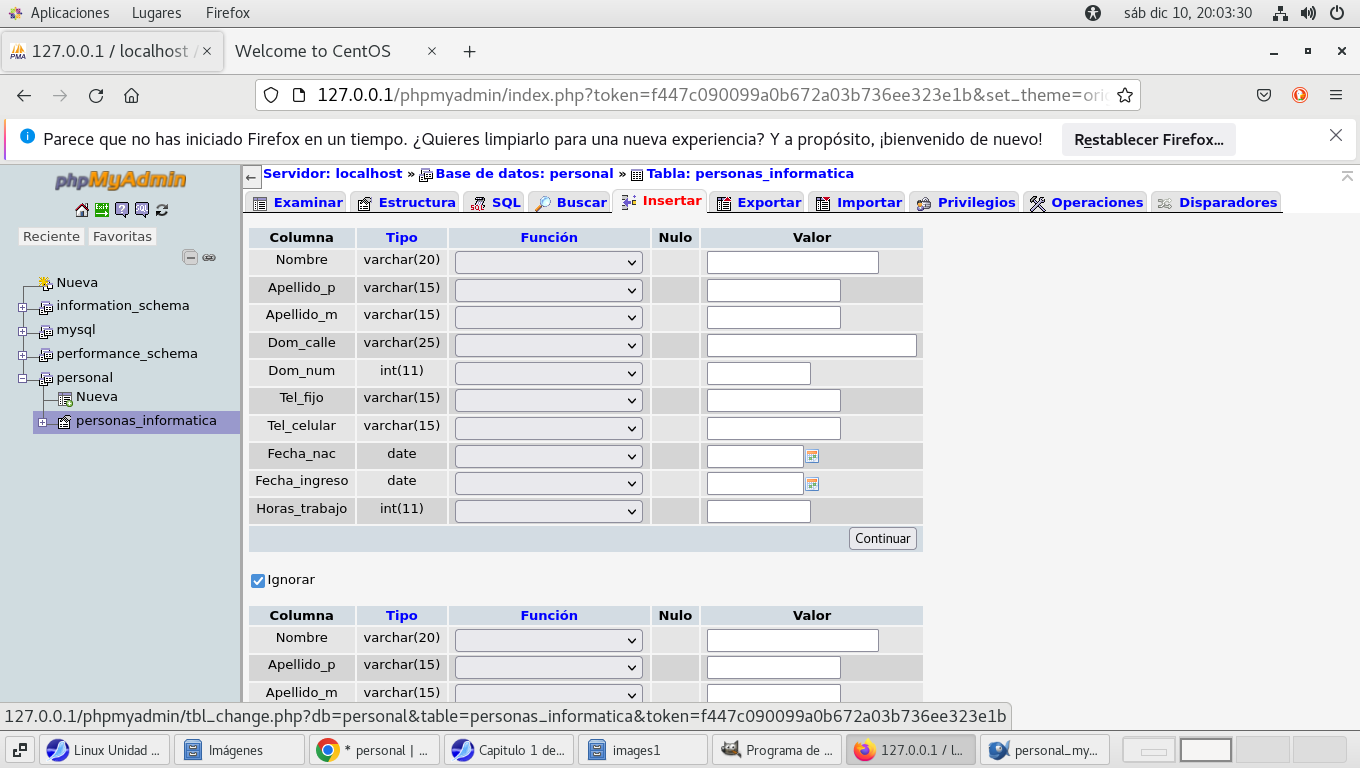
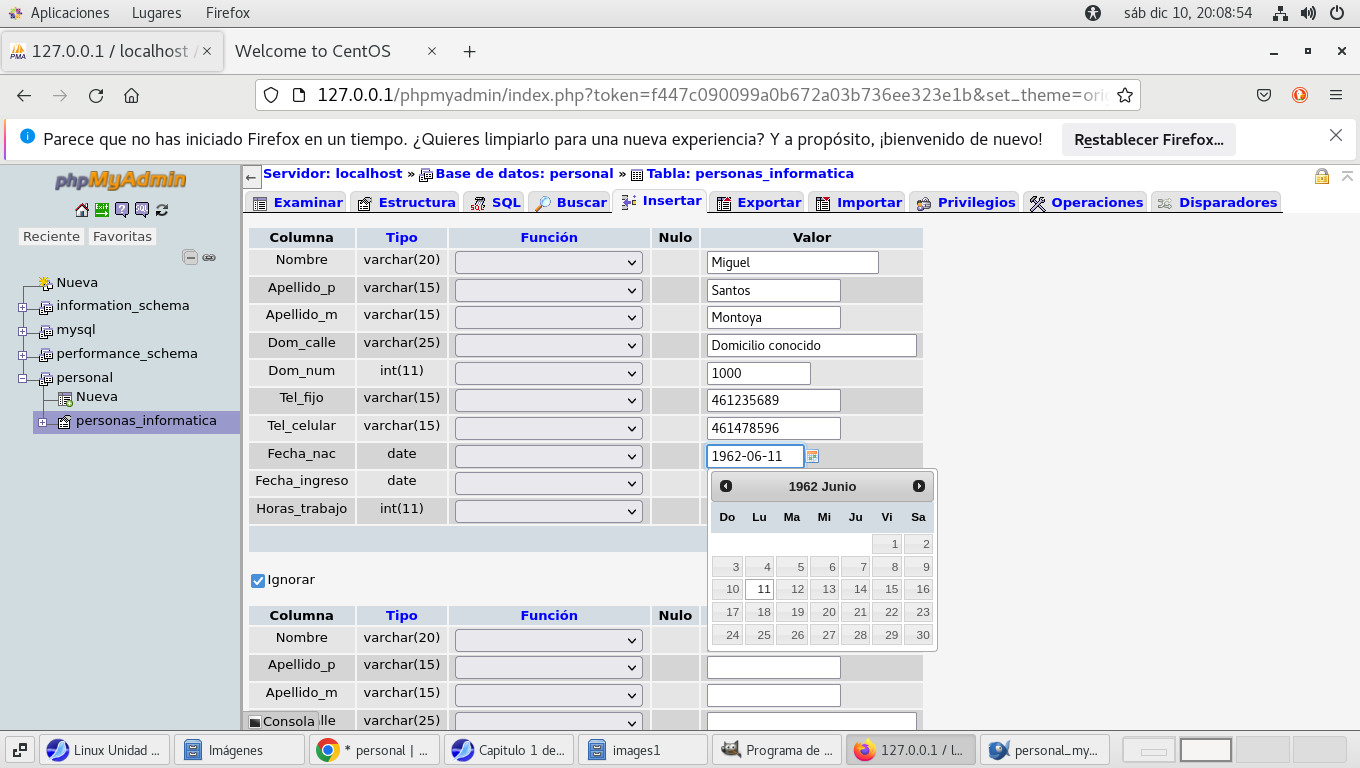
vemos un ejemplo de como llenar los datos,
recordemos que el formato de fecha es año mes día, para establecer
el formato de fecha que usamos debemos manipularlos, para
formatear la fecha y convertirla de YYYY-MM-DD a DD-MM-YYYY
hacemos lo siguiente:
SELECT date_format(fecha, "%d-%m-%Y") as fecha_formateada from
tabla;
Lo que importa aquí es el formato %d-%m-%Y (si quieres puedes usar
/ en lugar de -) con los modificadores. Si quieres ver la lista
completa de modificadores visita este enlace, ya que así puedes
crear cualquier formato de fecha.
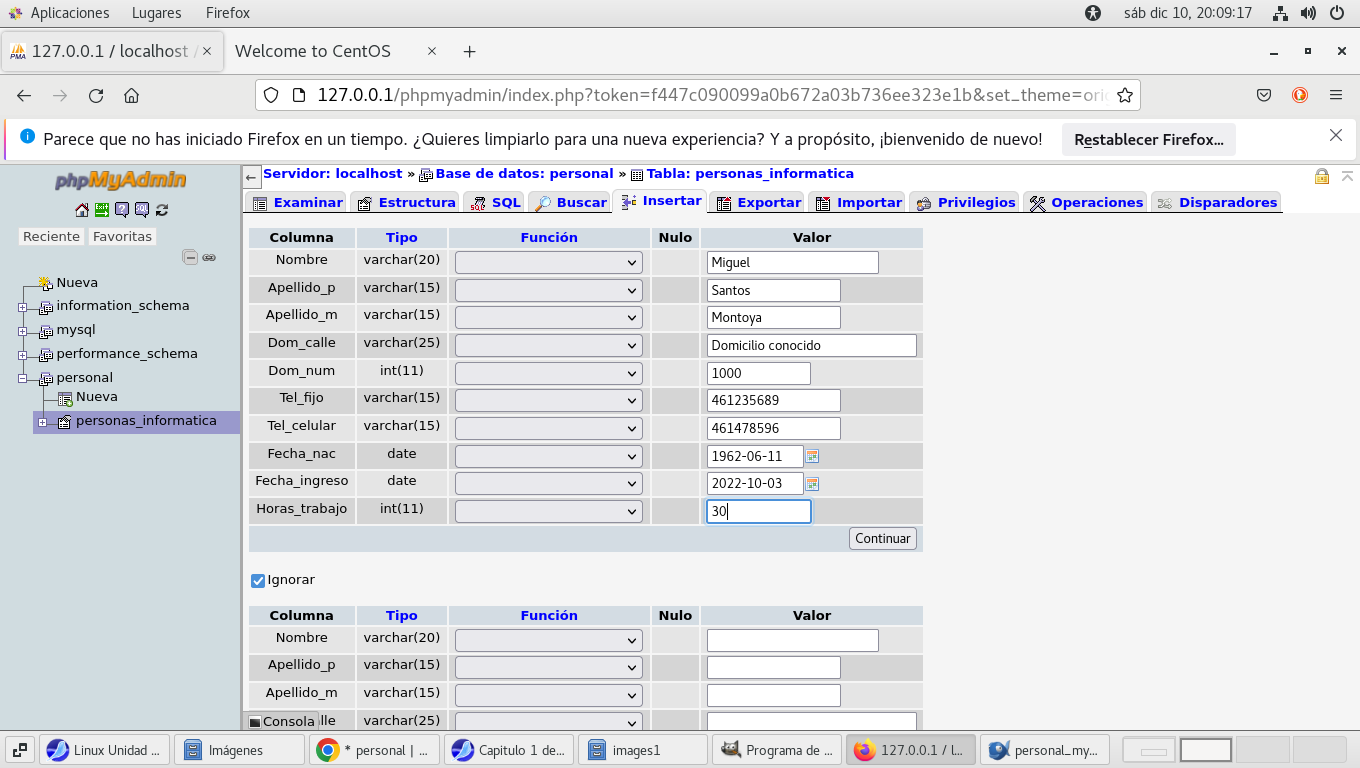
hacemos clic en el botón Continuar, y hemos
insertado una fila a la tabla, los campos se muestran en color
azul, mientras que los datos están en rojo, la forma de realizar
la insersion de datos en la tabla con un script de SQL es:
INSERT INTO base_de_datos.tabla ('campo1','campo2',.....)
VALUES ('dato1','dato2', ....);
usa el Botón Continuar en la parte inferior derecha.
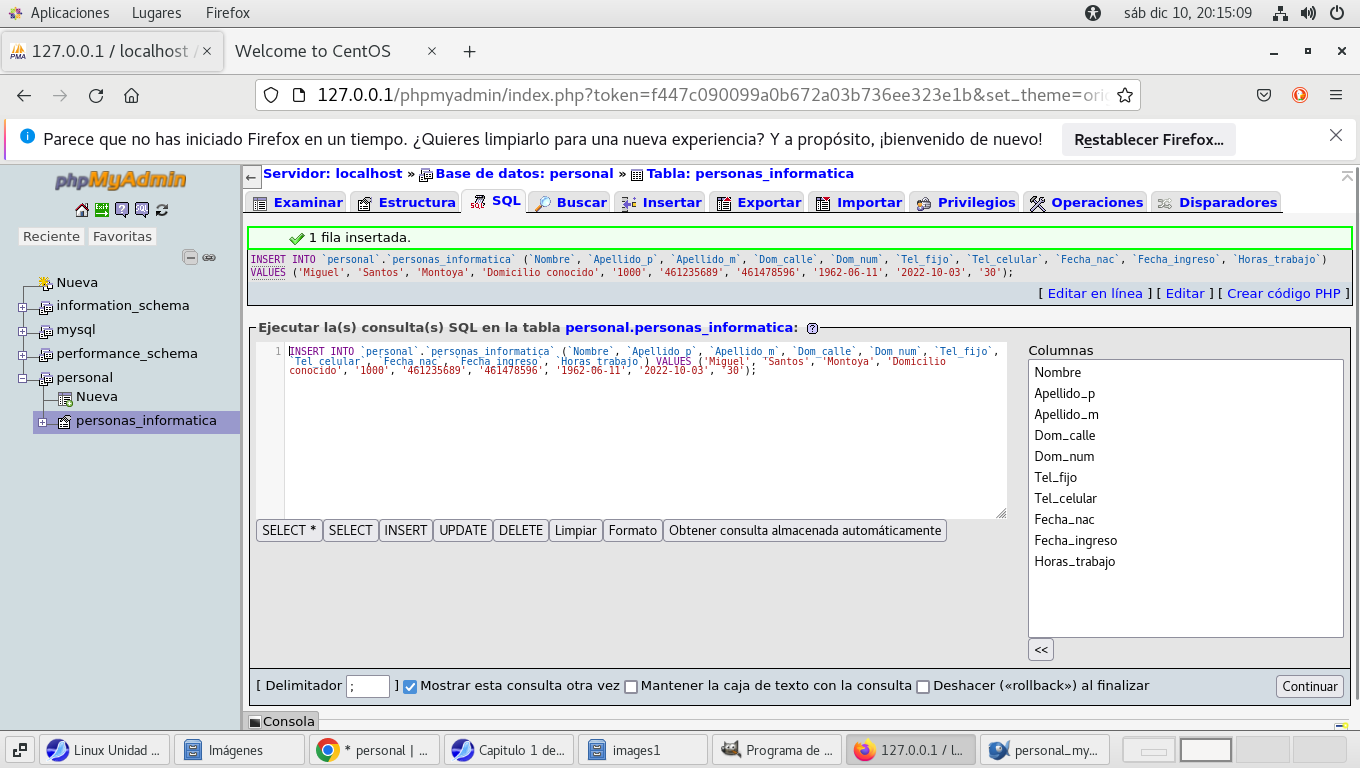
ahora aquí ya se inserto la fila de datos (registro) consultemos
lo que se ha almacenado en la tabla, hacemos clic en Examinar
(color rojo):
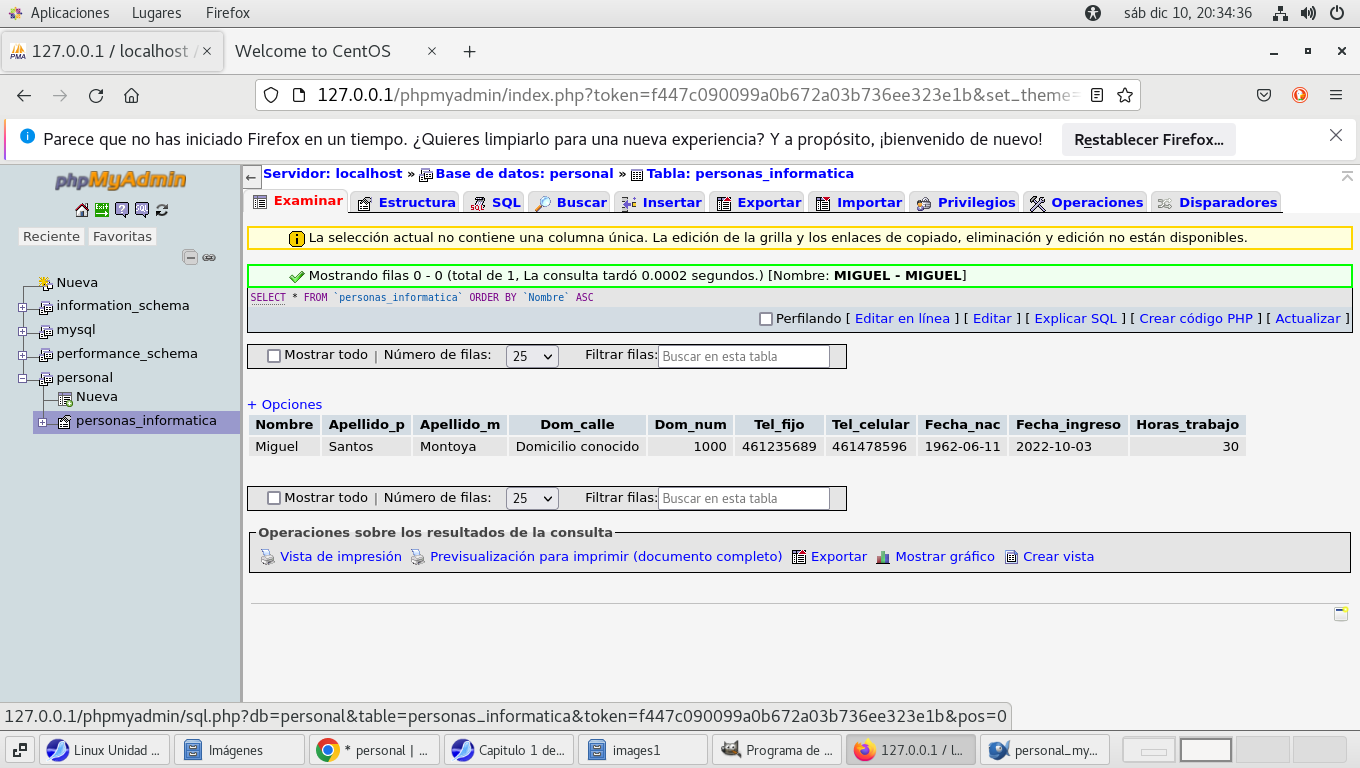
Ahora agreguemos otra fila (Registro) de datos (son para probar
algunas funciones):
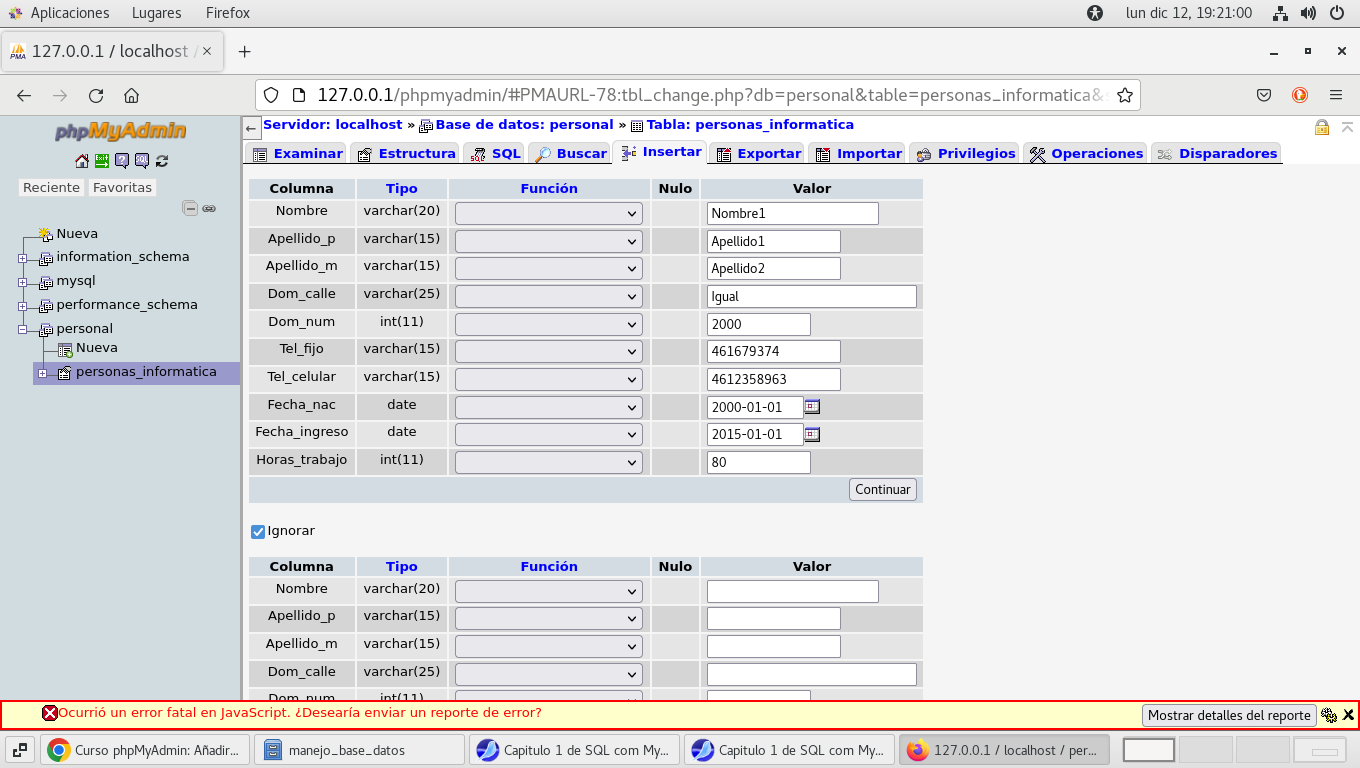
Clic en el botón Continuar (revisemos de nueva cuenta la
sentencia)
INSERT INTO nombre_table.base_de_datos (Nombre_campo1,
Nombre_campo2, ....) VALUES (dato_campo1,dato_campo2, ....);
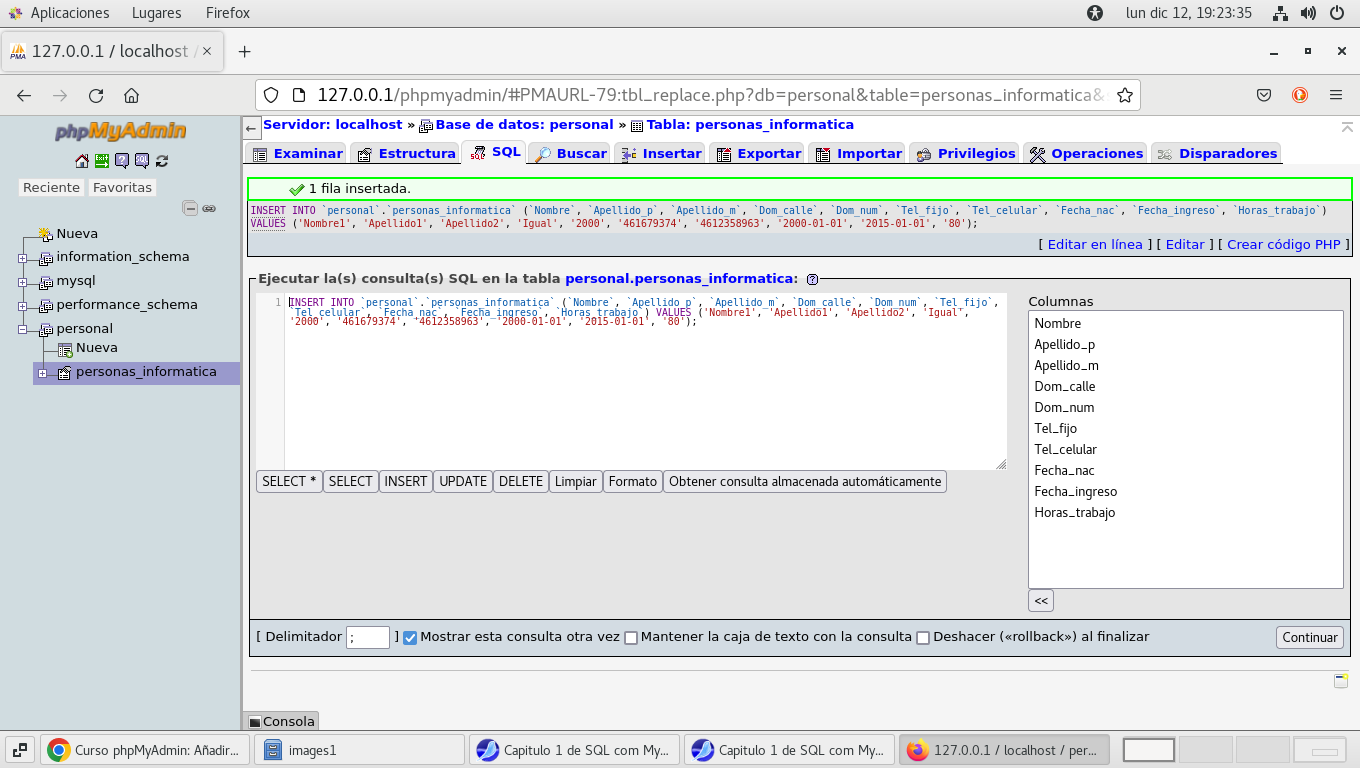
En Examinar:
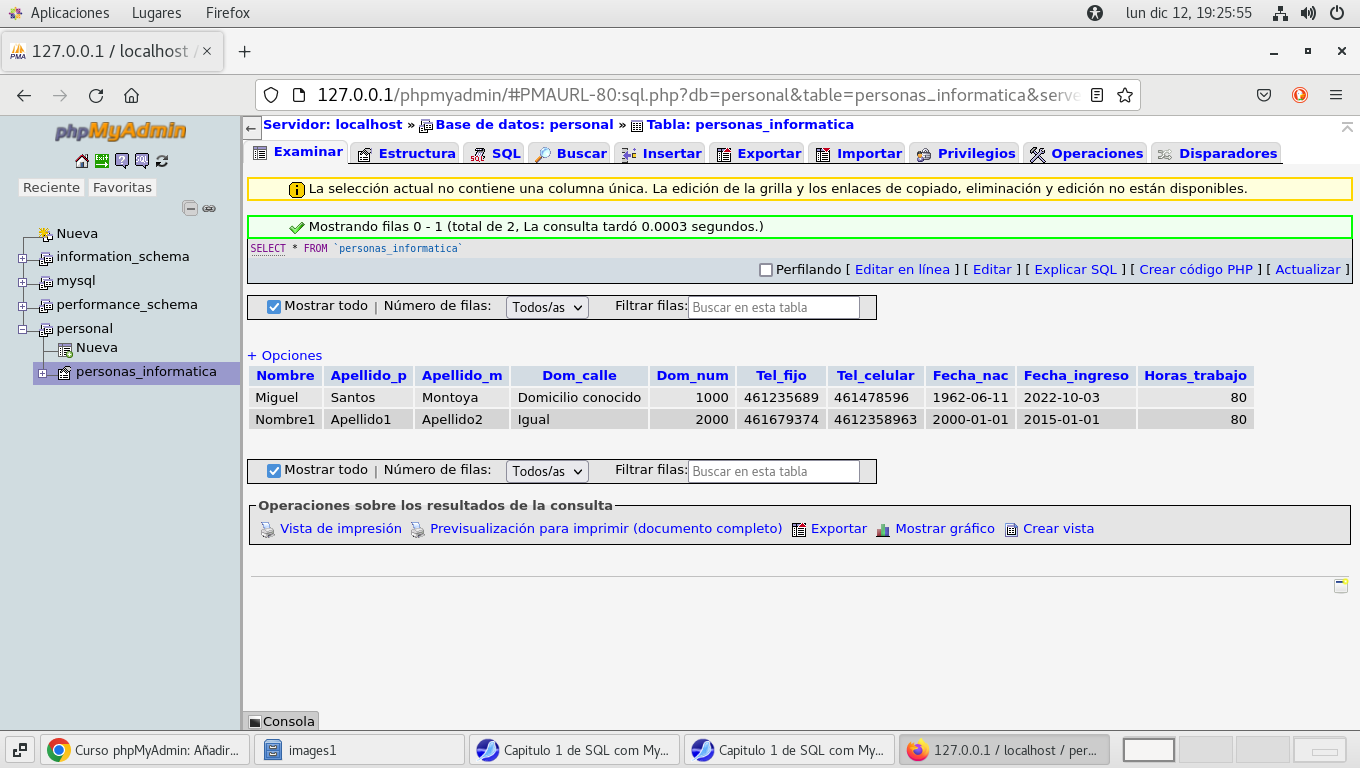
Podemos resumir lo que es la tabla con datos de
la siguiente forma:
Observemos que se añadió otro registro, pero
supongamos que quiero eliminar este registro, bueno aquí tenemos
un problema desde PhpMyAdmin y en general no es posible desde esta
interface borrar un solo registro ya que no existe un campo de
identificación en particular, si observamos con cuidado los campos
son bastante genéricos si hay un nombre repetido no podrá
distinguirlo de los demás que sean iguales, así que nuestra tabla
esta mal diseñada, y si, los lleve a un callejón sin salida pero
hay una forma de corregir esto.
En la pestaña SQL escriba la siguiente expresion:
ALTER TABLE
`personas_informatica` ADD COLUMN `Identificador` int NOT NULL
use el botón continuar
con esto agregaremos un campo llamado Indentificador en la tabla
personas_informatica:
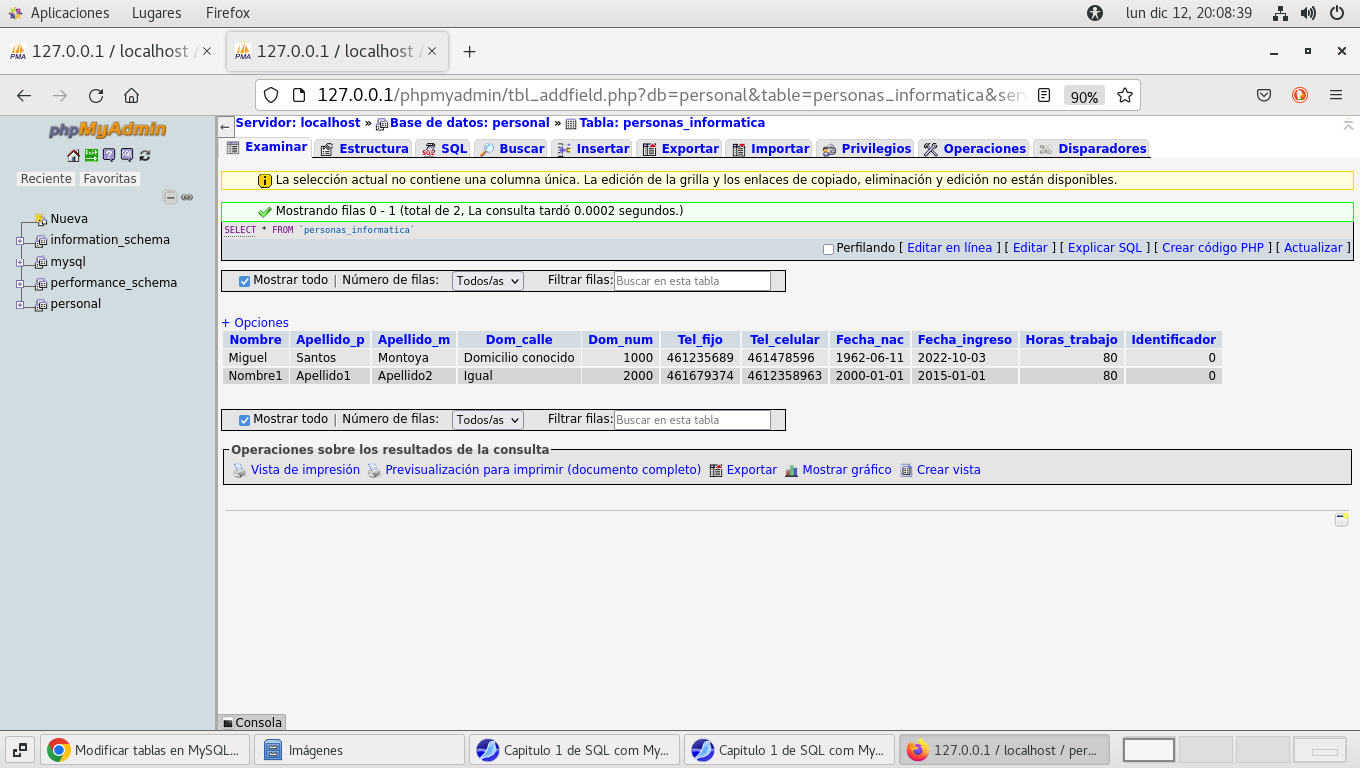
podemos ver que hay una leyenda en la parte superior :

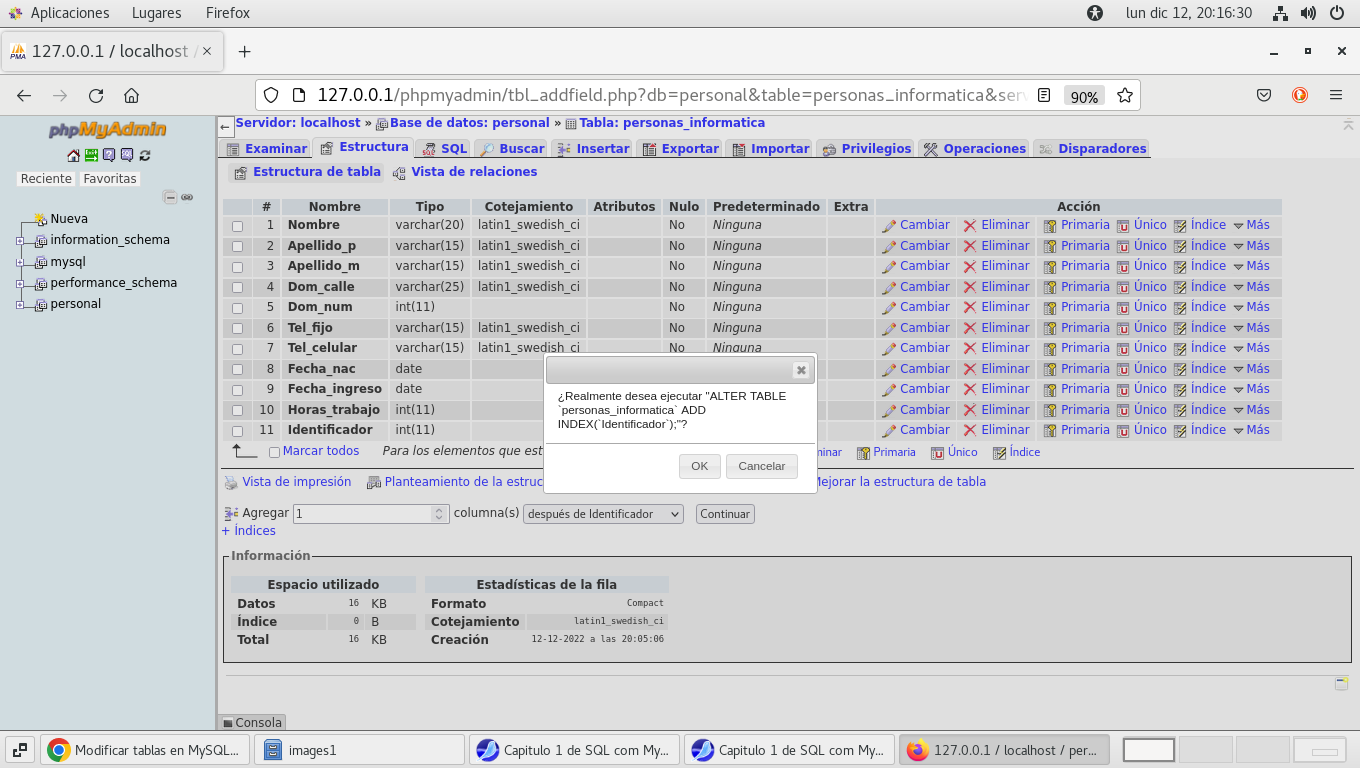
pues la solución es indicar este campo como INDEX (Indice), en
la pestaña Estructura (Esquema) al final se localiza el campo que
agregamos, y le establecemos INDEX:
Pasamos a la pestaña estructura y cambiamos los
valores al campo que insertamos, seleccionado el campo
Identificador con las características siguientes, y
Previsualizamos SQL:
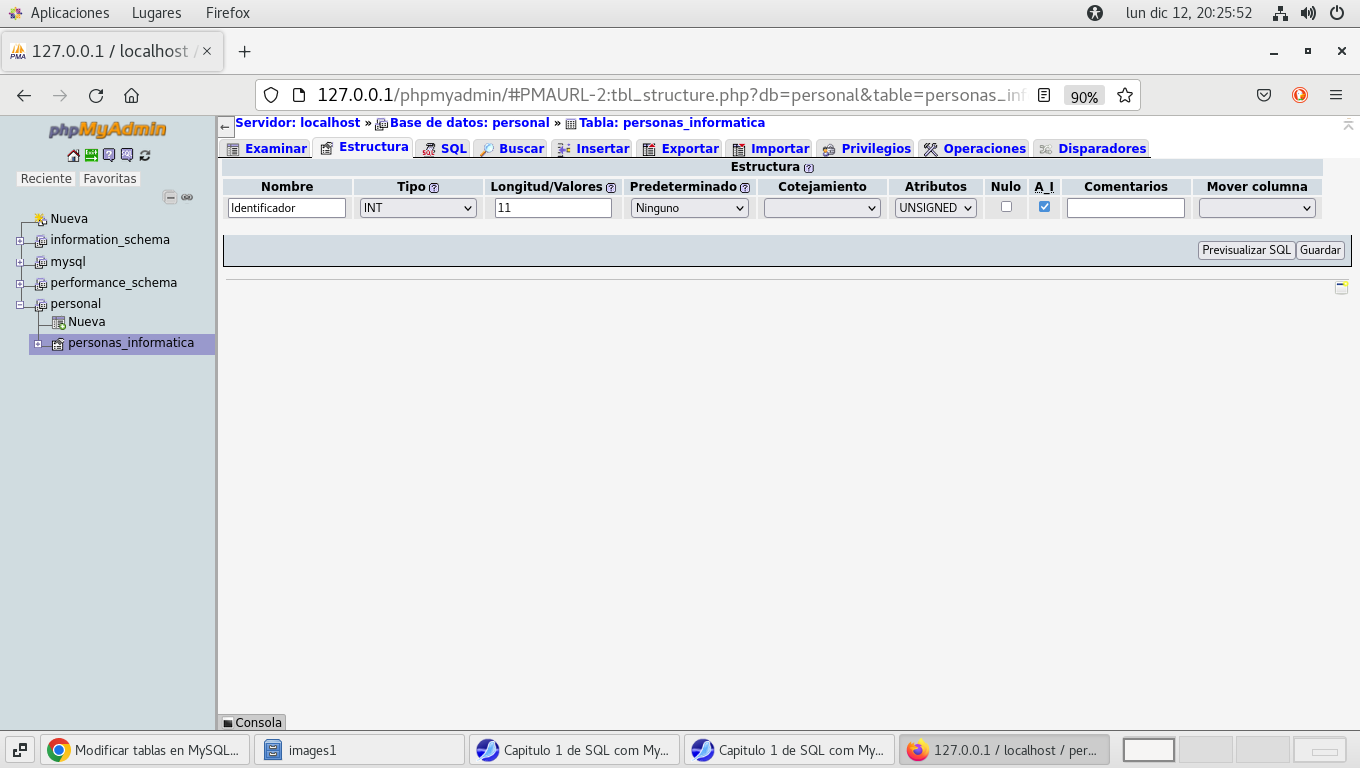
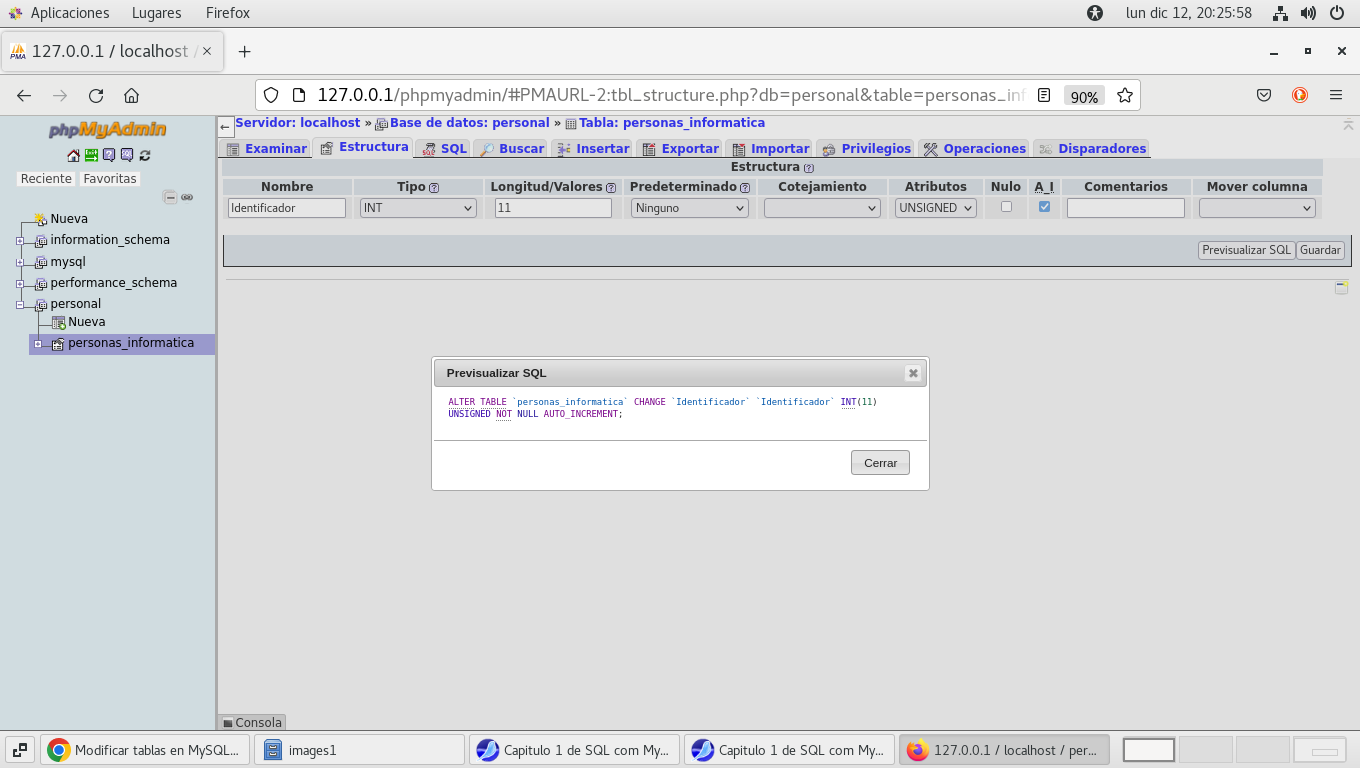
Al finalizar los cambios se verán así:
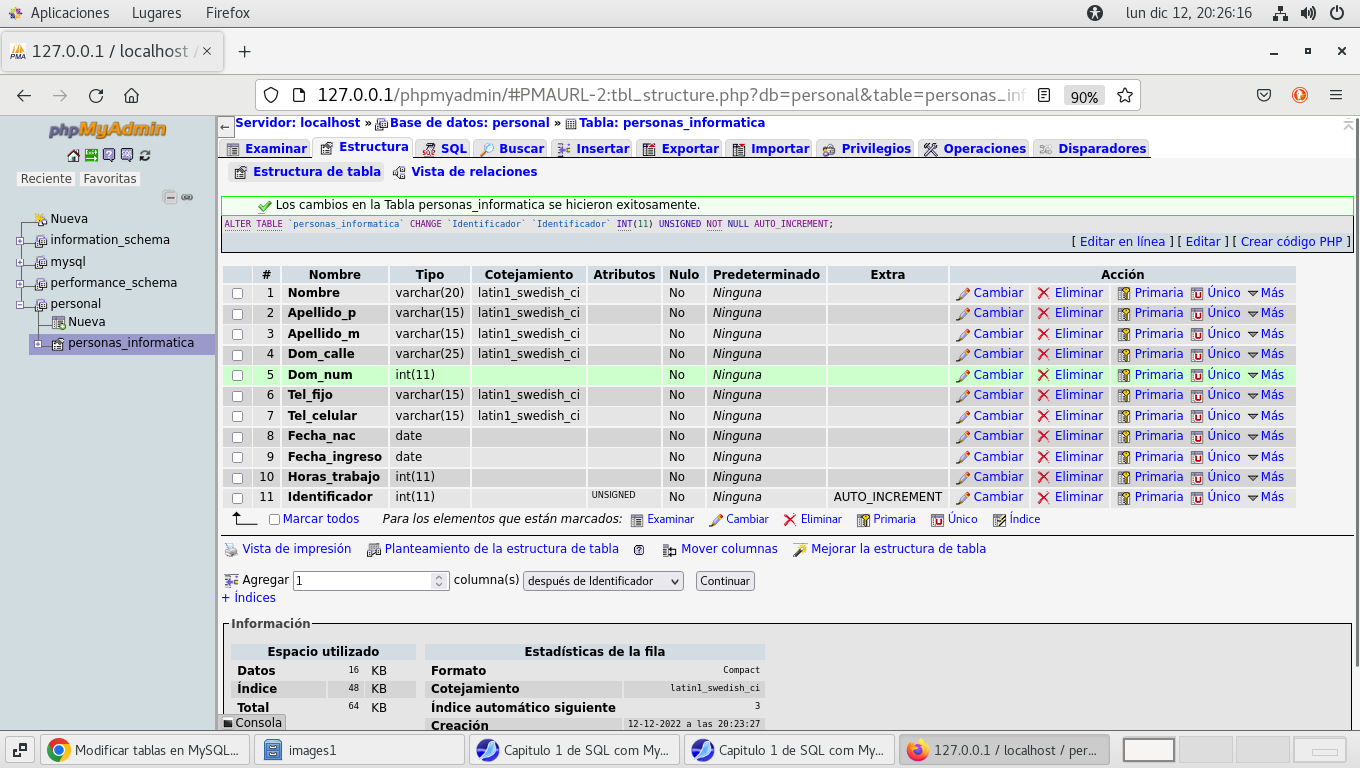
con ello ya puedo borrar el registro 2 de la tabla en la pestaña
SQL, simulamos la instrucción SQL:
DELETE FROM `personas_informatica` WHERE `Identificador`=2
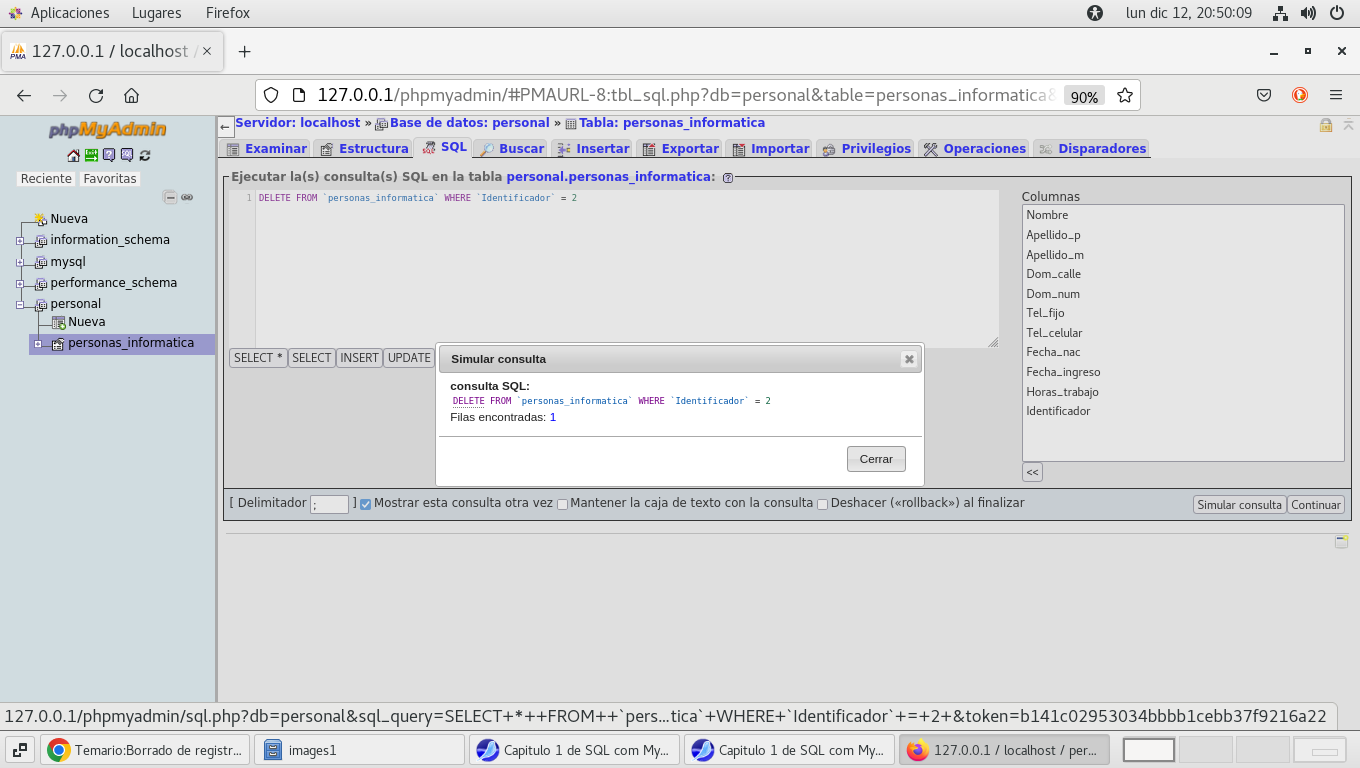
Ahora lo ejecutamos con cerrar y continuar, como se ve se debe
de llevar una secuencia definida para la creación de tablas
con ello borramos el registro, esto es muy
elaborado pero es una forma de corregir el problema, en lo
subsiguiente consideremos este campo identificador
para evitarnos estos problemas.
Realiza el siguiente Test 7 Unidad 1
Antes de proseguir con la creación de la base de
datos, las tablas que conforman la base de datos debemos entender
un concepto llamado NORMALIZACION:
La normalización (12)
en las bases de datos relacionales es uno de esos temas que, por
un lado es sumamente importante y por el otro suena algo
esotérico. Vamos a tratar de entender las formas normales (FN) de
una manera simple para que puedas aplicarlas en tus proyectos.
Entonces la normalización es el proceso de
organizar los datos de una base de datos. Se incluye la creación
de tablas y el establecimiento de relaciones entre ellas según
reglas diseñadas tanto para proteger los datos como para hacer que
la base de datos sea más flexible al eliminar la redundancia y las Ambigüedades
Los datos redundantes desperdician el espacio de
disco y crean problemas de mantenimiento. Si hay que cambiar datos
que existen en más de un lugar, se deben cambiar de la misma forma
exactamente en todas sus ubicaciones. Un cambio en la dirección de
un cliente es mucho más fácil de implementar si los datos sólo se
almacenan en la tabla Clientes y no en algún otro lugar de la base
de datos.
Redundancia. Se llama así a los datos que
se repiten continua e innecesariamente por las tablas de las
bases de datos.
Ambigüedades. Datos que no clarifican
suficientemente el registro al que representan.
Existen nueve formas diferentes de
normalización, Primera Forma Normal (1FN), Segunda Forma
Normal (2FN), Tercera Forma Normal (3FN), Forma Normal Boyce-Cood,
Cuarta Forma Normal, Quinta Forma Normal o Forma Normal de
Proyeccion-Unión, Forma Normal de Proyeccion-Union Fuerte, Forma
Normal de Proyeccion-Union Extra Fuerte, Forma Normal Clave de
Dominio. Solo trataremos los 3 primeros.
Primera Forma Normal (1FN)
Esta FN nos ayuda a eliminar los valores repetidos y no atómicos
dentro de una base de datos.
Formalmente, una tabla está en primera forma normal si:
-
Todos los atributos son atómicos. Un
atributo es atómico si los elementos del dominio son
simples e indivisibles.
-
No debe existir variación en el
número de columnas, es estar cambiando las columnas de
forma que no se identifiquen con su propósito, es decir no
estar modificando la tabla cada vez que sea necesario
incorporar mas datos.
-
Los campos no clave deben
identificarse por la dependencia funcional, es decir se
expliquen con su nombre y su proposito.
-
Debe existir una independencia del
orden tanto de las filas como de las columnas; es decir,
si los datos cambian de orden no deben cambiar sus
significados.
-
Se traduce básicamente a que si
tenemos campos compuestos como por ejemplo
“nombre_completo” que en realidad contiene varios datos
distintos, en este caso podría ser “nombre”,
“apellido_paterno”, “apellido_materno”, es lo que se
conoce como atomizar los campos, separar los elementos que
conforman un campo como en este ejemplo.
-
Los campos deben ser tales que si
reordenamos los registros o reordenamos las columnas, cada
dato no pierda el significado.
Resumiendo la primer forma normal indica que las columnas no
deben repetirse, y si es el caso deberan ponerse en tablas
separadas.
Ejemplo:
Vea la tabla llamada clientes:
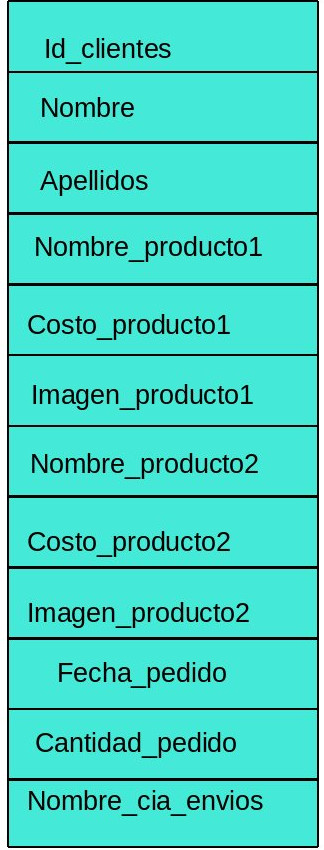
Lo que podemos apreciar es que en la tabla los
campos Nombre_producto1, Costo_producto1, Imagen_producto1, se
repiten con otros campos del mismo tipo, por lo que en lugar de
tener limitado a 3 productos en esta tabla los pasemos a otra
tabla donde los podemos relacionar no solo con 3, podrían ser mas
productos que un cliente compre, usando la relación entre tablas.
Con esto en mente podemos hacer estas tablas:
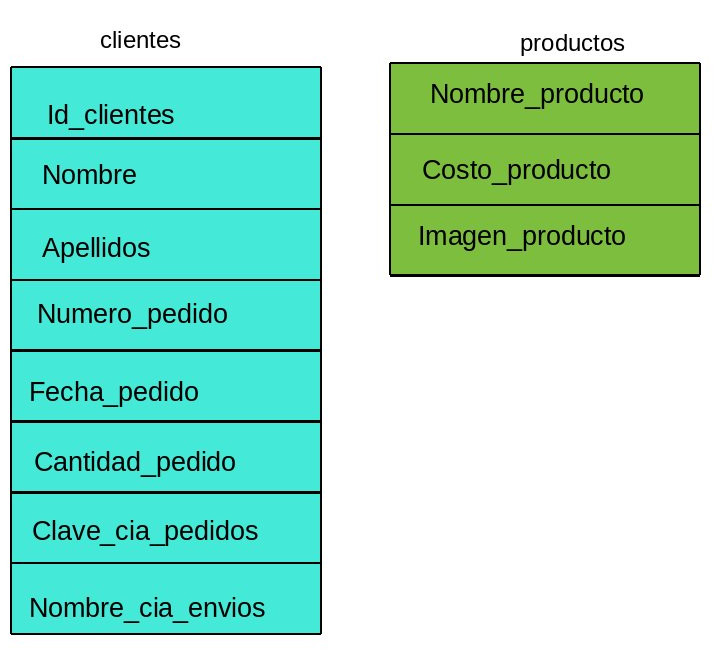
ya tenemos 2 tablas, ahora tenemos que
relacionar ambas tablas por medio de un elemento en comun, y es
con un campo identico en ambas tablas para que pueda "localizar"
el producto "A" de la tabla cliente con el producto "A" de la
tabla productos.
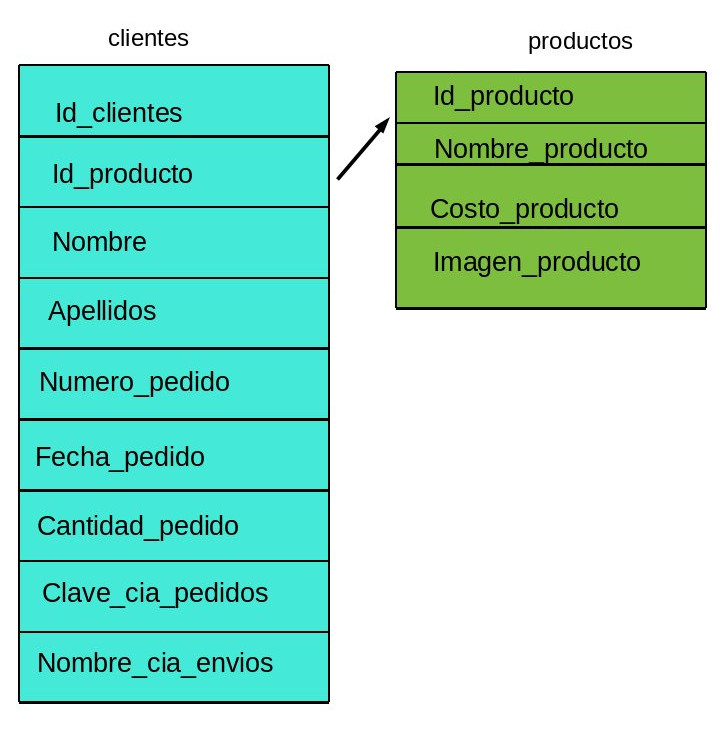
Esta es una relación de uno a varios, es el primer ejemplo de
esto aunque no terminamos con estas tablas.
La segunda Forma Normal (2FN)
Esta FN nos ayuda a diferenciar los datos en diversas entidades.
Formalmente, una tabla está en segunda forma normal si:
-
Está en 1FN
-
Sí los atributos que no forman parte de ninguna clave
dependen de forma completa de la clave principal. Es decir,
que no existen dependencias parciales.
-
Todos los atributos que no son clave principal deben
depender únicamente de la clave principal.
Lo anterior quiere decir que sí tenemos datos que pertenecen a
diversas entidades, cada entidad debe tener un campo clave
separado.
ELIMINAR LOS DATOS REDUNDANTES
Por ejemplo:
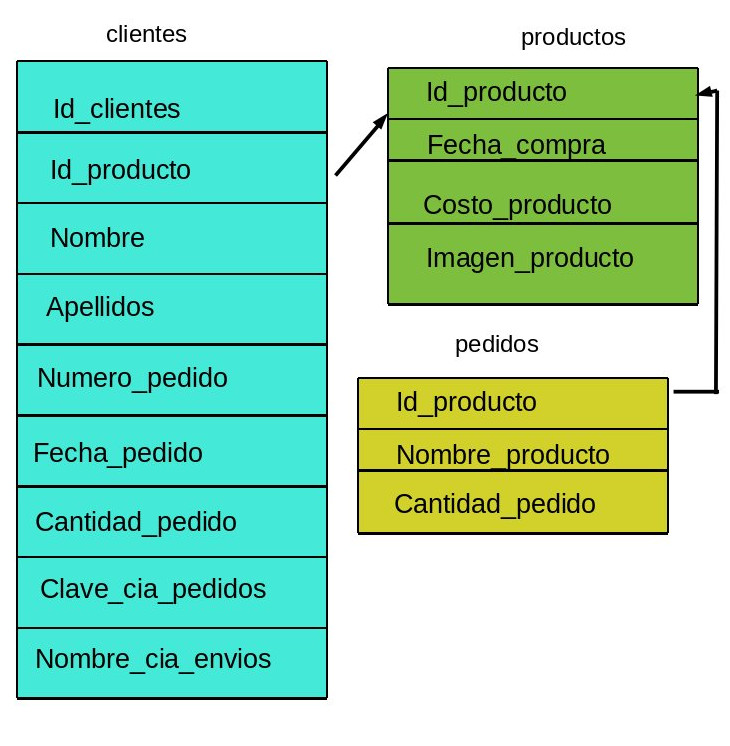
La desventaja es que se lleva tiempo en realizar la
normalizacion.
Observando la tabla clientes el campo Nombre_cia_envios no es
dependiente del cliente.
Tercera Forma Normal (3FN)
Esta FN nos ayuda a separar conceptualmente las entidades que no
son dependientes.
-
Se encuentra en 2FN
-
No existe ninguna dependencia funcional transitiva en los
atributos que no son clave
Esta FN se traduce en que aquellos datos que no pertenecen a la
entidad deben tener una independencia de las demás y debe tener un
campo clave propio, quedando de la siguiente manera.
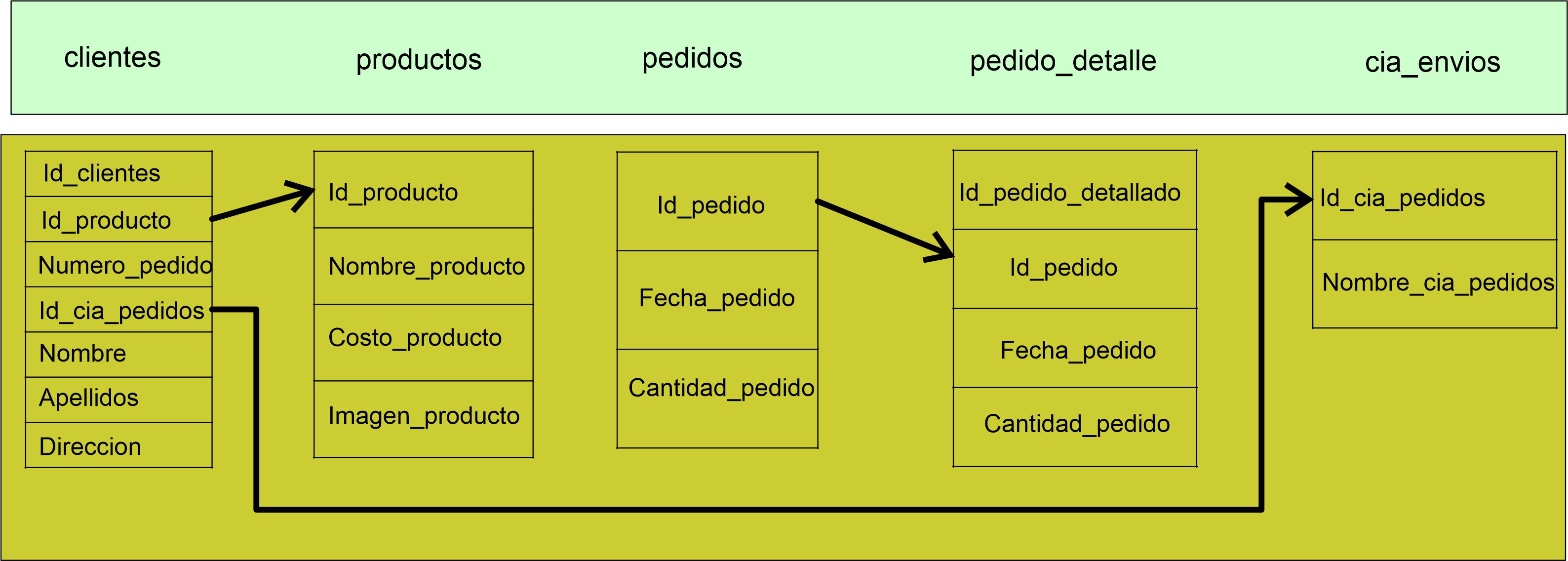
Realiza el siguiente Test 8 Unidad 1
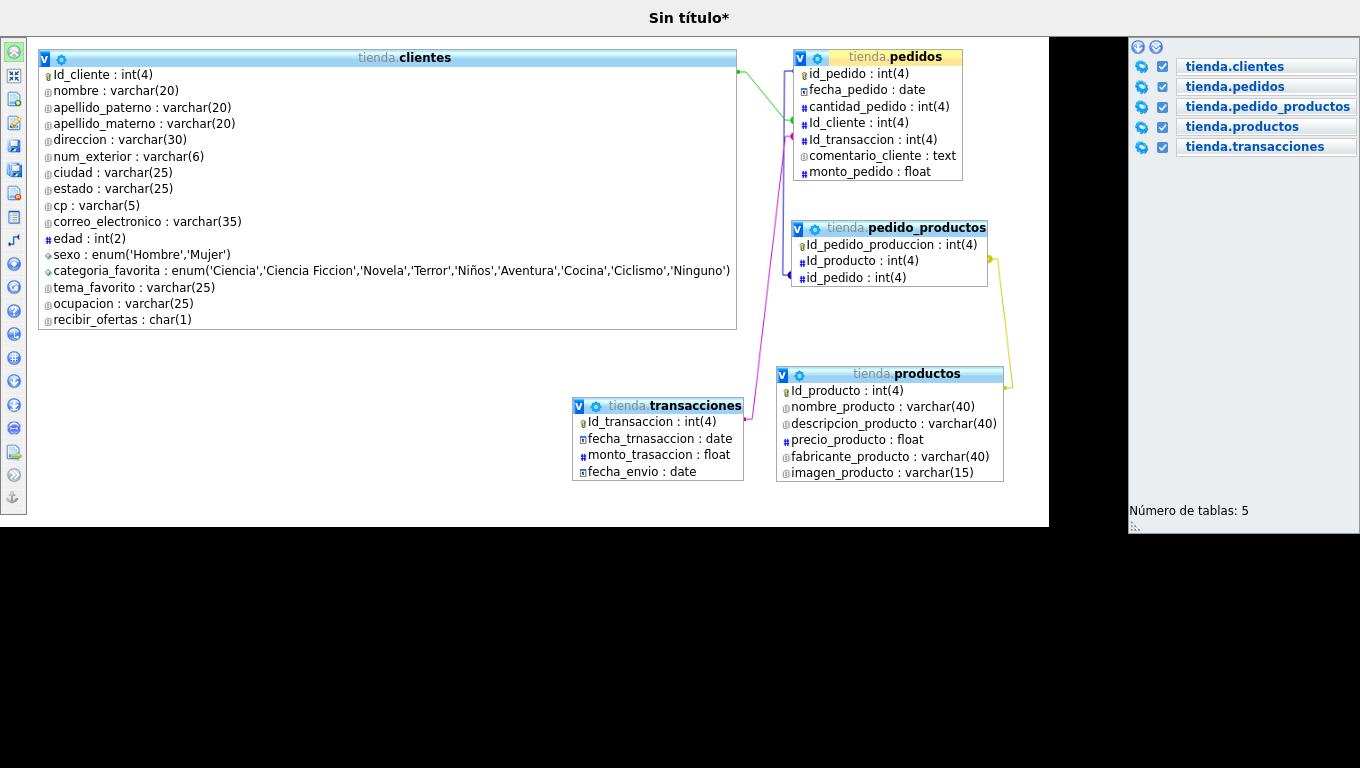
Definición
de las relaciones
Éste es el último paso antes de crear su base de
datos. Definir las relaciones entre las tablas no siempre es una
tarea fácil. Primero que nada debe determinar si existe una
relación. Segundo, si existe una relación, debe determinar su
tipo.
La forma más fácil de determinar las relaciones
es observando el diagrama creado en el paso anterior. Tome una
tabla/objeto y vea si se relaciona lógicamente o interactúa con
alguna(s) otra(s). Por ejemplo, en la base de datos de la librería
tiene objetos cliente, libro y transacción. Yo vería el objeto
cliente y me preguntaría si existe alguna relación o interacción
con el objeto libro. En este ejemplo sí la hay. Un cliente debe
comprar un libro de la librería para ser un cliente; por lo tanto,
existe una relación.
Después me haría la misma pregunta, pero esta
vez con el objeto transacción.
De nuevo, existe una relación entre ellos.
Cuando un cliente compra un libro, se crea una
transacción; por lo tanto, aquí también existe una relación.
Tomaría ahora el objeto libro y vería si existe
alguna relación.
Tiene una con el objeto cliente, pero no con el
objeto transacción.
Un libro puede existir sin ninguna transacción.
El objeto transacción interactúa con el cliente, pero no con el
libro.
Todo esto puede parecer algo confuso al
principio, pero con el tiempo y la experiencia será capaz de
establecer las relaciones de manera rápida y fácil.
El siguiente paso en este proceso es determinar
qué tipo de relaciones existen. En una base de datos relacional
hay tres tipos de relaciones: uno a uno, uno a varios, varios a
varios
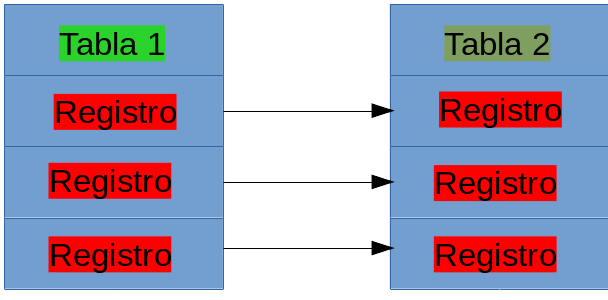
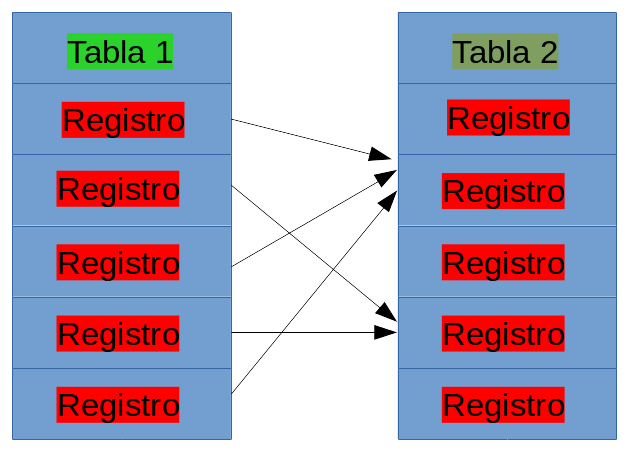
Uno a uno
En una relación uno a uno, un registro en la
tabla uno debe tener un registro en la tabla dos, y si la tabla
dos tiene un registro, debe existir un registro correspondiente en
la tabla uno.
En el ejemplo, podría existir una relación uno a
uno entre las tablas Tabla 1 y Tabla 2. Para cada registo debe
existir una transacción. Para crear esta relación dentro de la
base de datos debe añadir un campo que permita establecer esta
relación. El campo que normalmente se usa para esto, se conoce
como campo clave (primary key). mas adelante se veran ejemplos de
campos clave. Por ahora, sólo es necesario saber que el campo
clave, es un campo único dentro de la tabla. Ningún otro registro
tendrá el mismo valor para este campo. El propósito de esto es
distinguir un registro de los demás en esa tabla.
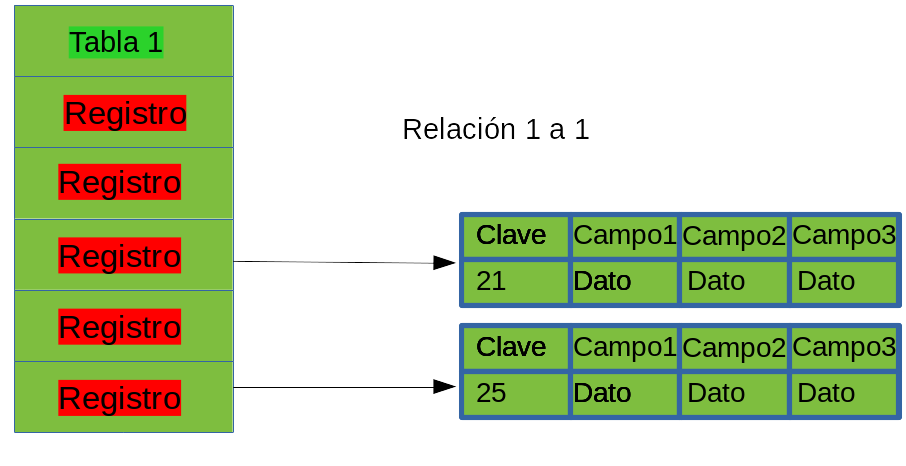
Por esta razón la mayoría de los diseñadores de
bases de datos llaman a este campo, el campo ID. Por ejemplo, la
Tabla 1 podría tener un campo lD_cliente y la Tabla 2 podría tener
un campo ID_cliente (puede ser de nombre diferente pero el tipo de
datos y formato deberán ser iguales, sin embargo en la mayoría de
los programadores prefieren usar el mismo Nombre campo y sus
propiedades en ambas tablas para ubicarlas.)
Para establecer una relación uno a uno debe
designar a una de las tablas como primaria y a la otra como
secundaria. Generalmente ésta es una decisión arbitraria en
relaciones uno a uno. Para hacer esto más fácil, escoja la tabla
que se afectará en primera instancia cuando agrege un nuevo
registro a la base de datos. Esta tabla primaria contendrá un
campo clave. Ambos campos serán únicos dentro de la tabla
secundaria. Esto creará una relación uno a uno.
Uno a varios
Una relación uno a varios ocurre cuando un
registro de la tabla 1 puede tener varios registros
correspondientes en la tabla 2, y la tabla 2 tiene varios
registros que corresponden a un solo registro de la tabla 1.
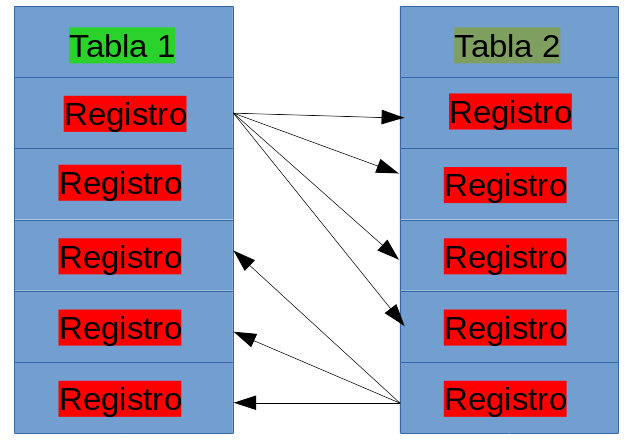
Una relación varios a varios
La relación varios a varios puede causar algunos
problemas. Puede introducir datos redundantes, lo cual viola las
reglas de normalización. La normalización se cubre con más detalle
el día 5 “Normalización de sus datos”. Una relación varios a
varios también es difícil de mantener. Borrar y añadir registros
es peligroso. Por ejemplo, supongamos que la librería tiene muchas
bodegas en todo el país. Cada bodega almacena libros para surtir.
Hay varios libros que podrían estar en una bodega y muchas bodegas
que podrían contener un libro en particular. ¿Qué pasa si añade
una nueva bodega? Tendría que añadir nuevamente cada título de
libro en su tabla de bodegas. Esto sería un poco tedioso. Para
remediar esta situación debería contar con una tabla intermedia
para enlazar estas tablas entre sí. Esto crearía dos relaciones de
uno a varios. Esta tabla debería tener las claves primarias de
ambas tablas. Cuando se coloca un libro en una bodega, se tendría
que agregar un registro en esta tabla intermedia, la cual debería
contener el campo clave de la tabla libros y el campo clave de la
tabla bodegas. Si necesitara saber qué libros están en una bodega,
podría consultar la tabla intermedia para averiguarlo. A primera
vista puede parecer que se está haciendo más compleja la base de
datos. Le puedo asegurar que esto bien vale la pena. Es
verdaderamente difícil implementar una relación varios a varios
sin la ayuda de una tabla intermedia.
Realiza el siguiente Test 9 Unidad 1
Base de datos tienda
Ahora crearemos una base de datos que comprende
varias tablas, para llevar el control de venta de libros, primero
es definir el proceso de ventas y debemos entrevistar a los
trabajadores que reciben a los compradores y como se realiza todos
los proceso de recepción de libros, el almacenamiento, y venta /
distribución:
1.- Cliente entra a comprar un libro.
2.- Llenar solicitud de membresía.
3.- Llenada ala solicitud, permitir búsqueda de libro en la base
de datos.
4.- Cuando se localizá el libro llevar con un link las
características.
5.- Ya localizado el libro, hacer solicitud de envió del libro a
una dirección.
(hay que hacer un análisis
adicional y consiste que una persona puede comprar un libro, sin
necesidad de inscribirse como un cliente habitual, eso se debe
de considerar en el momento de relizar la aplicacion para que
solo afecte a las tablas de pedidos y no al resto de estas
tablas)
A partir de esto ya podemos identificar algunos objetos que
serian las tablas:
Cliente
Producto
Pedidos
Transaccion
Regresemos a DBDesigner en Internet
Comecemos por asignar un nombre a la base de datos : tienda (en
este ejemplo realizaremos la tabla en la base de datos, y haremos
cambios a las tablas un ultimo momento para que se pueda apreciar
la forma de edición de la tablas)
y en esta ocasión agregamos una descripción, a cada tabla:
Añadir Campo, y
comencemos por colocar un campo para identificación de un campo y
que sea llave primaria, cuando marcamos en la selección Llave
primaria, también se activara Auto Incrementable, en este caso le
retiraremos la marca solo quedaria Llave Primaria
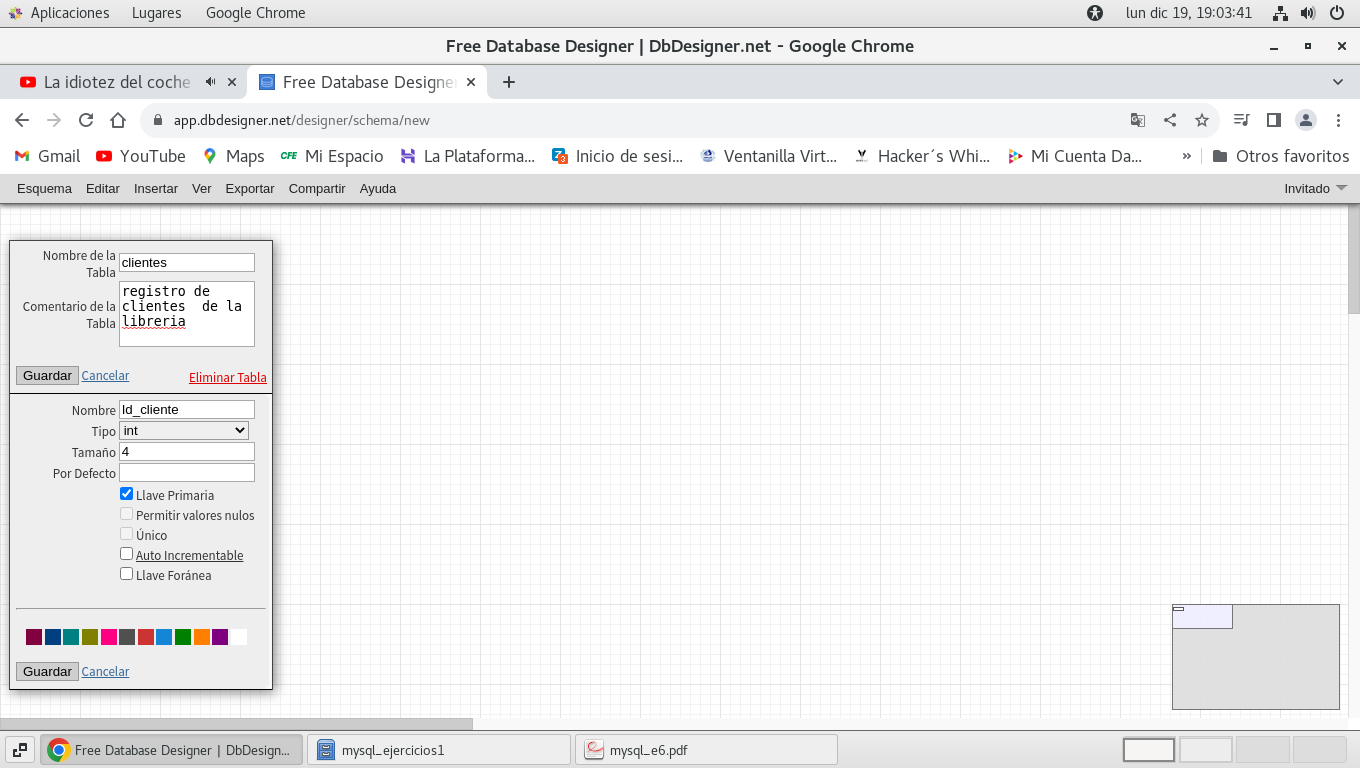
Para el ingreso de datos cliente se requiere un
identificador que puede ser numérico o alfanumérico, (clave por
cliente, ya que cada cliente debe tener un identificador único, ya
que si fuera por nombre se repetirían y seria una verdadera
confusión, y no es buena practica poner como identificador un
nombre porque se repiten muchos), y sera designado como llave
primaria (primary key) ya que esta sera la que relacione esta
tabla con otra para leer información adicional, este campo deberá
ser igual en nombre y propiedades que se encuentren en las otra(s)
tablas para poder "relacionar" un campo con otra tabla, la tienda
tiene algunas reglas que debemos de considerar antes de seguir
* El cliente no puede
consultar su base de datos a menos que este registrado (que sea
miembro)
* Un libro no puede ser comprado a menos
que sea colocado en el pedido.
* El cliente debe de tener un nombre y una
dirección.
* El producto debe de tener un nombre y un
precio.
* La fecha de envió o puede ser anterior a
la fecha de pedido.
* El sexo solo puede ser M (masculino) o F
(femenino).
* El monto de lo pagado debe ser igual a
la cantidad pedida o la suma de los pedidos.
* El monto pagado no puede ser un valor
negativo
completemos los registros de la tabla clientes queda así:
(estos ejemplos no son correctos del todo, hay ciertos errores
que iremos conociendo, y corrigiendo para que se consideren en el
momento de hacer tablas en las bases de datos, conociendo las
causas y sus soluciones)
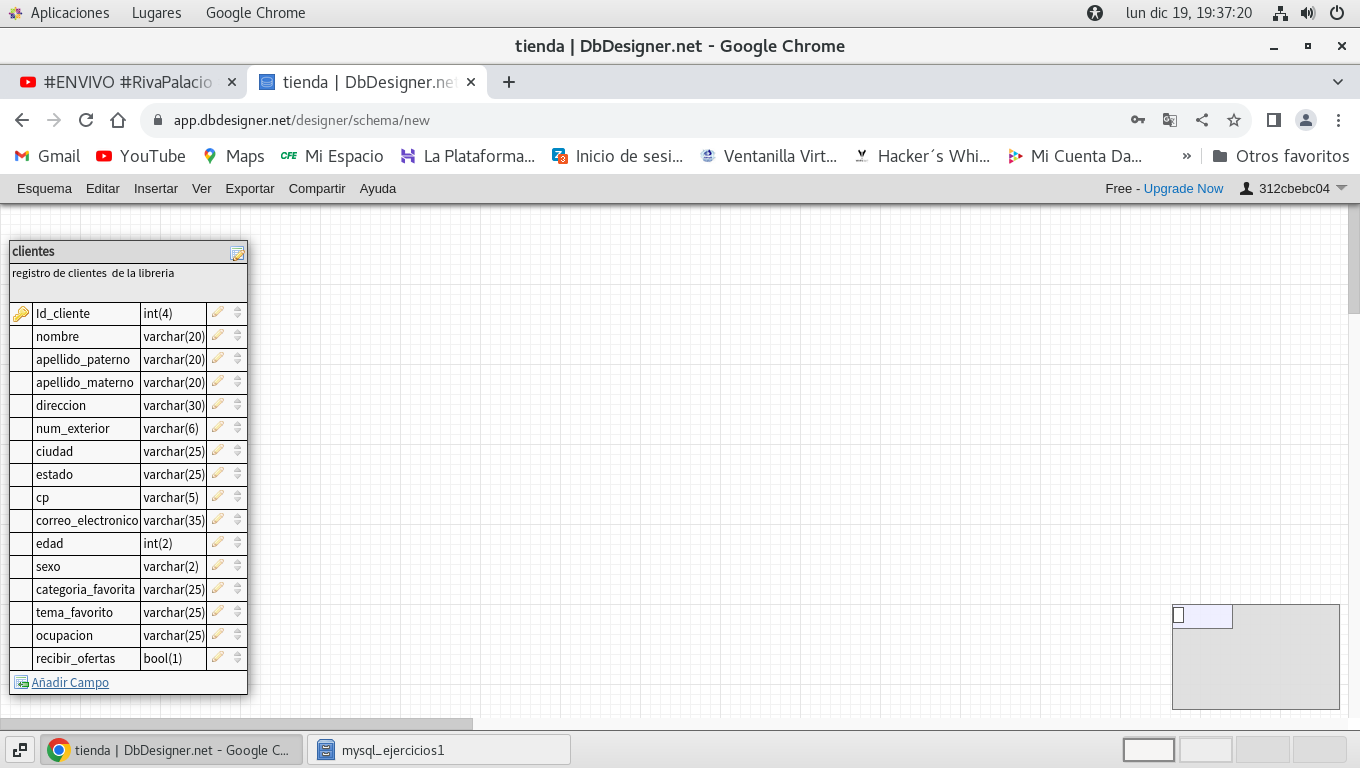
Al revisar esta tabla podemos ver que se esta atomizando los
campos de los datos.
Ahora pasemos a productos, cada producto tiene un precio y un
nombre
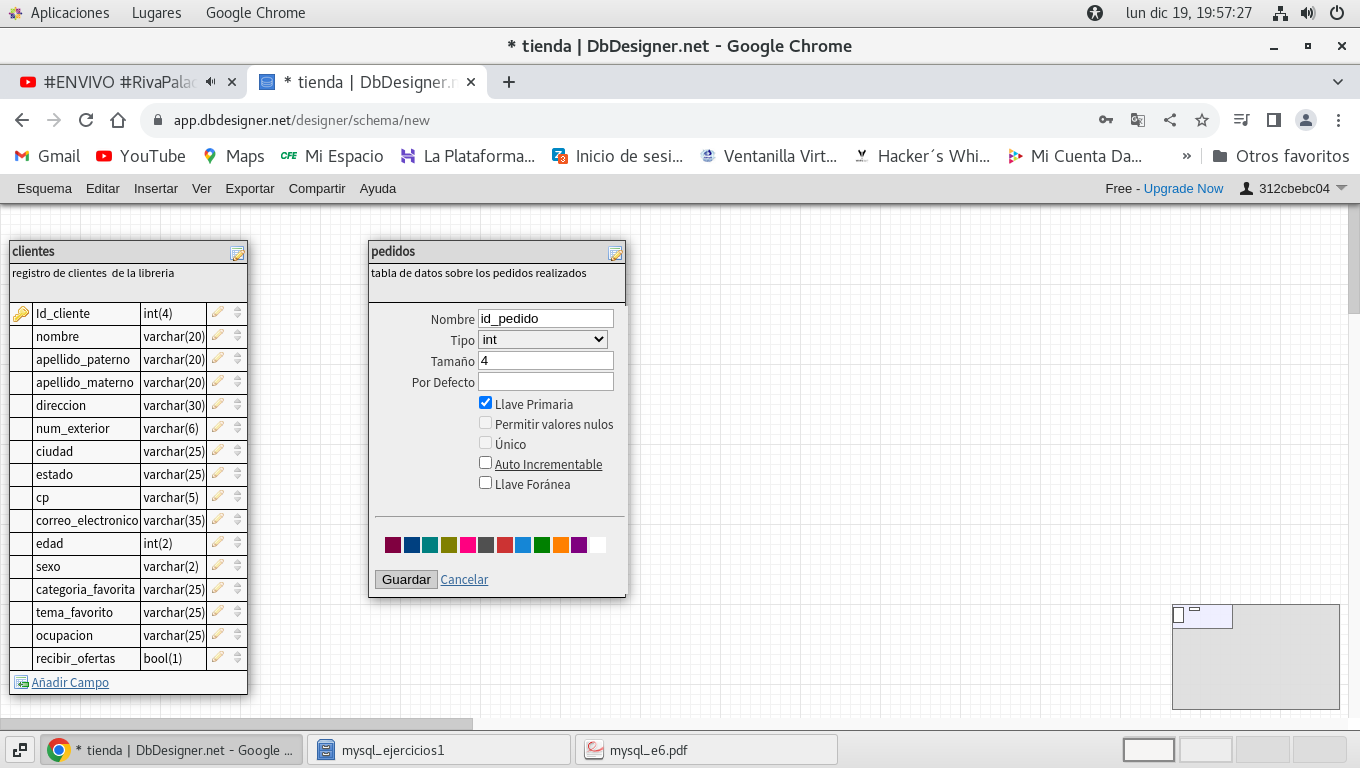
crearemos un campo para identificar el pedido, id_pedido (tengan
cuidado de no confundir los nombres de los campos de relación, en
este caso es con i no con I, esto es para darle seguimiento a esta
llave primaria - llave foranea)
Completemos la tabla pedidos:
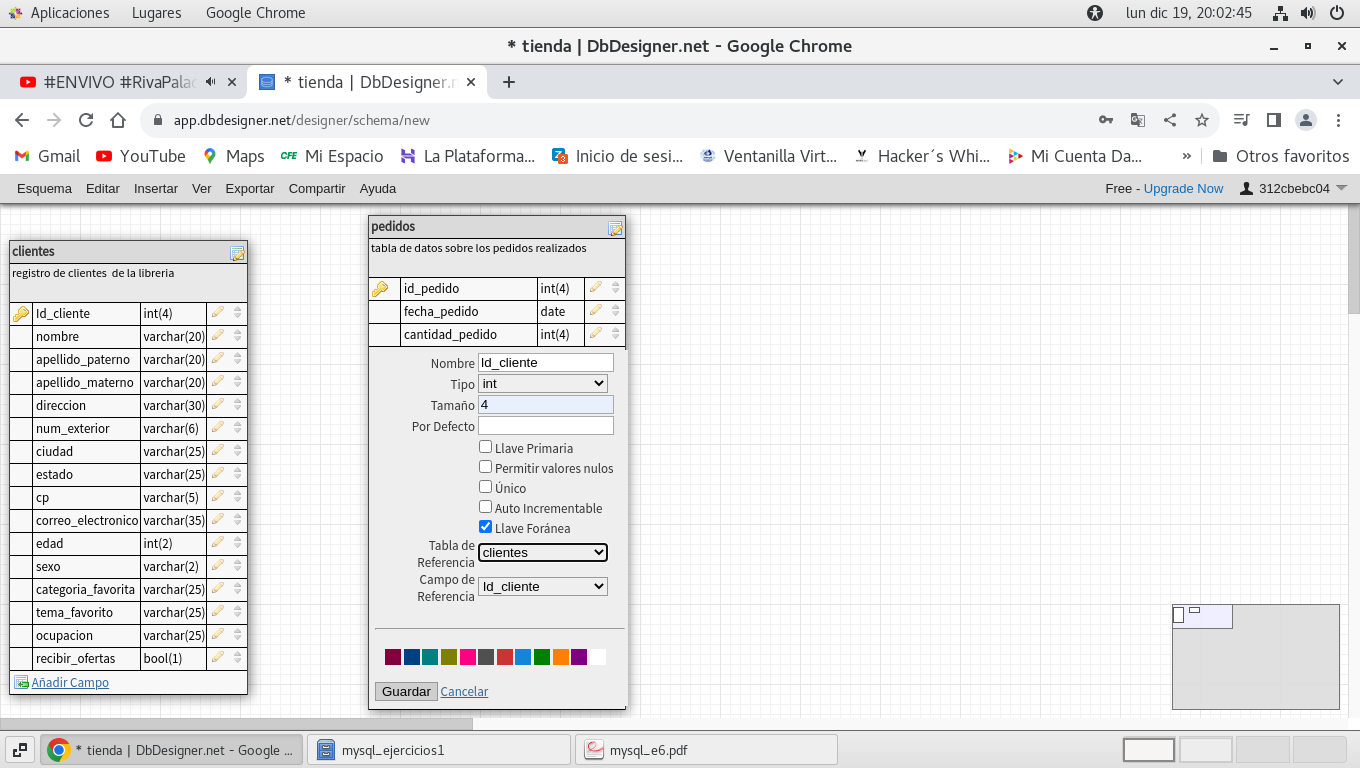
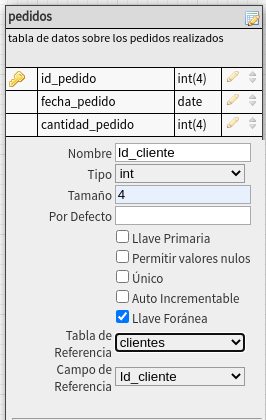
En este caso estamos relacionado esta tabla, con
la de clientes por medio del campo Id_cliente (recuerde que debera
ser igual a campo designado en clientes, y este campo deberá ser
Llave Foránea, que es la que relaciona ambas tablas, por esa razón
al indicar este campo se muestra la tabla de referencia
(clientes), y el campo de referencia (Id_cliente).
En la parte inferior de
este cuadro de dialogo, estan los conceptos de Tabla de
referencia y de Campo de referencia, deberemos de
verificar que esta tabla "Tenga la referencia correcta a la
tabla", como se aprecia, debe de referirse a la tabla clientes y
el campo Id_cliente.
como se observa se realiza la "relación entre
estas tablas", ahora hay un campo id_transaccion, que mas adelante
se "relacionara" con otra tabla.
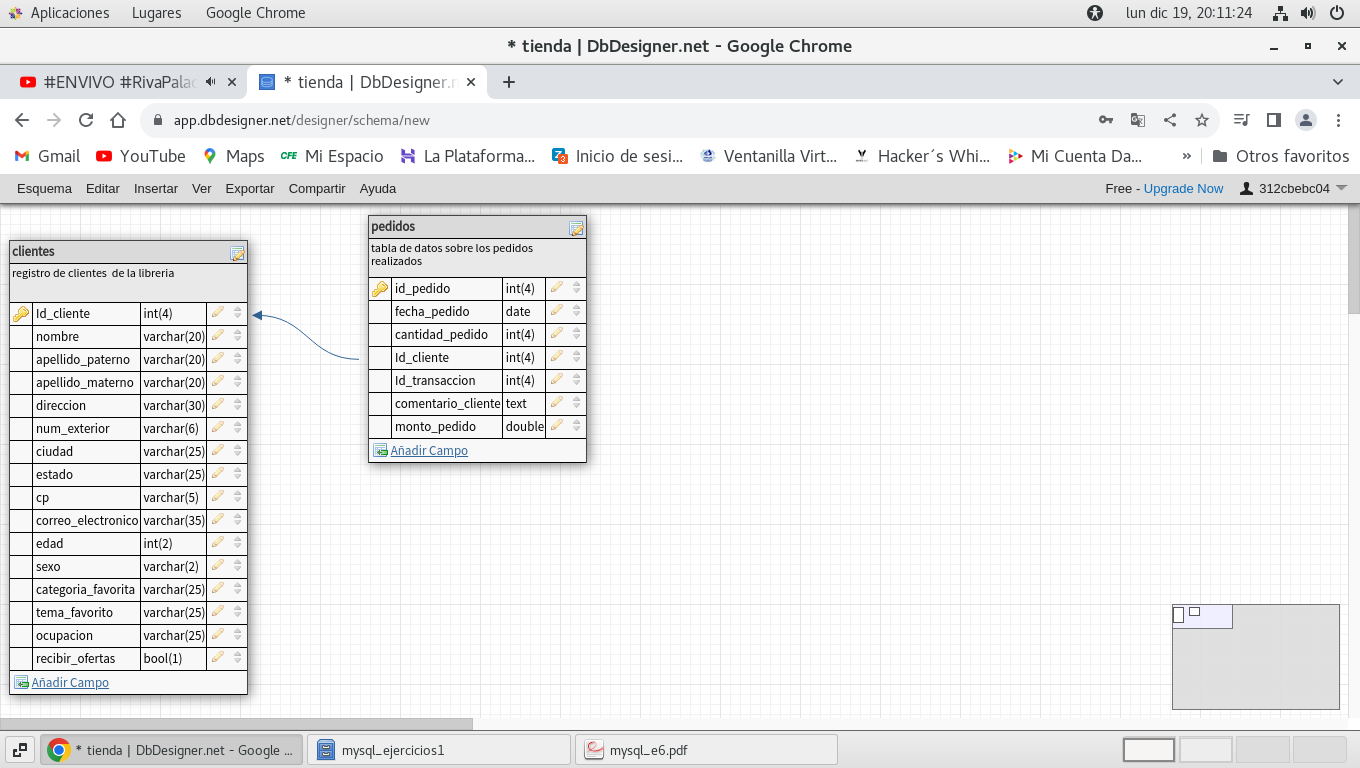
Observemos que hay un campo de tipo double, en
la tabla pedidos es correcto esto ?
(esto nos llevara a un problema en cuanto
generemos la tabla en PhpMyAdmin.)
y en la tabla clientes hay otro campo que introducimos de forma
erronea, lo identificas ?
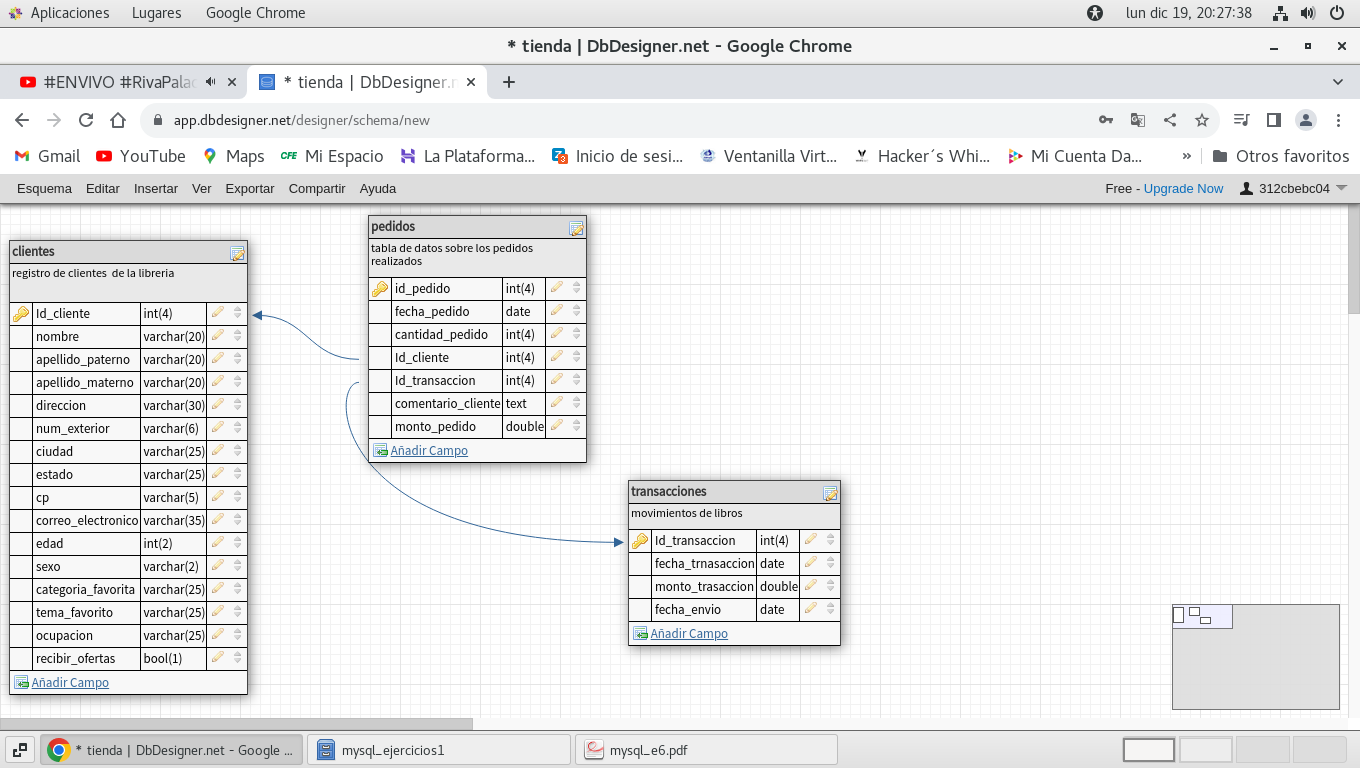
Pasemos a crear la tabla transacciones, vea que
tenemos una clave primaria, a lo cual debemos de regresar mas
adelante a la tabla pedidos para modificarlo y agregar una clave
foránea.
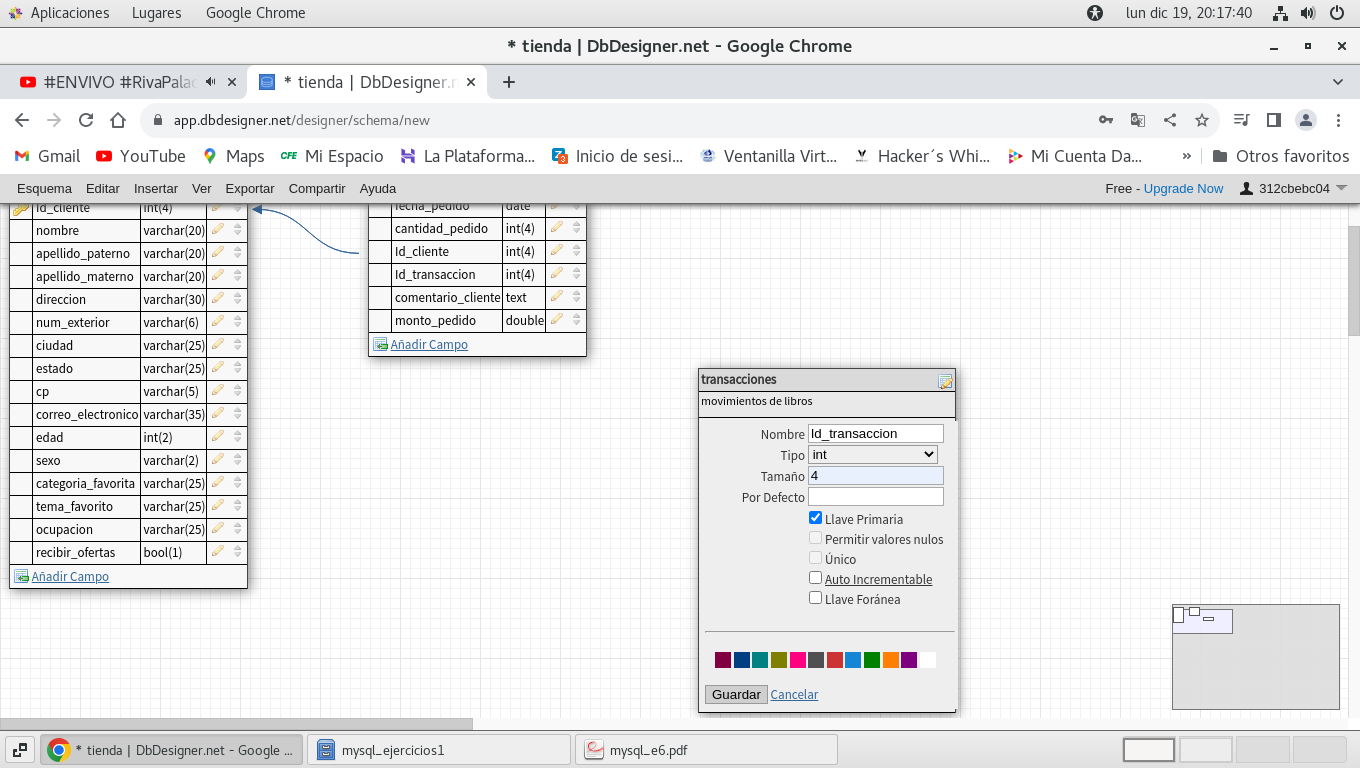
así quedaría la tabla de transacciones
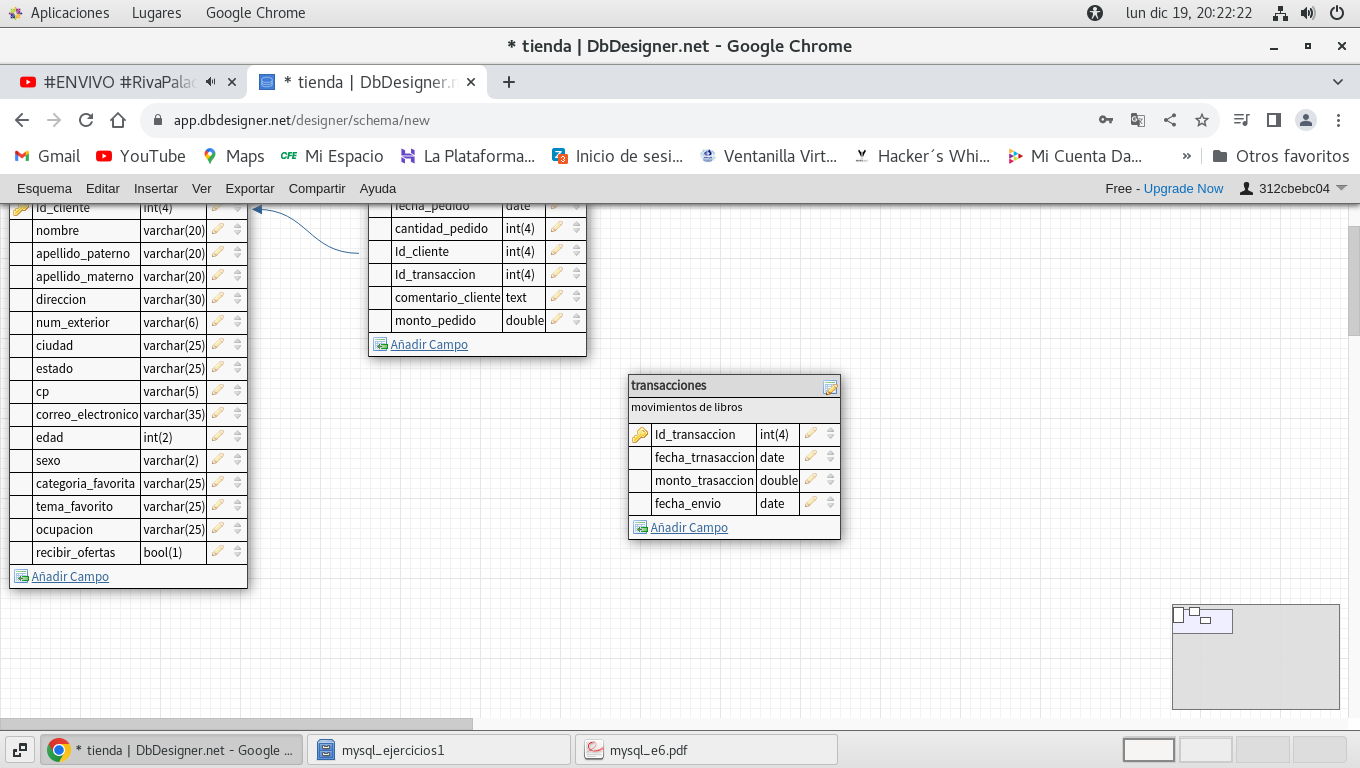
ahora modifiquemos la tabla pedidos, para modificar el campo
Id_transaccion para pasarlo a clave foránea.
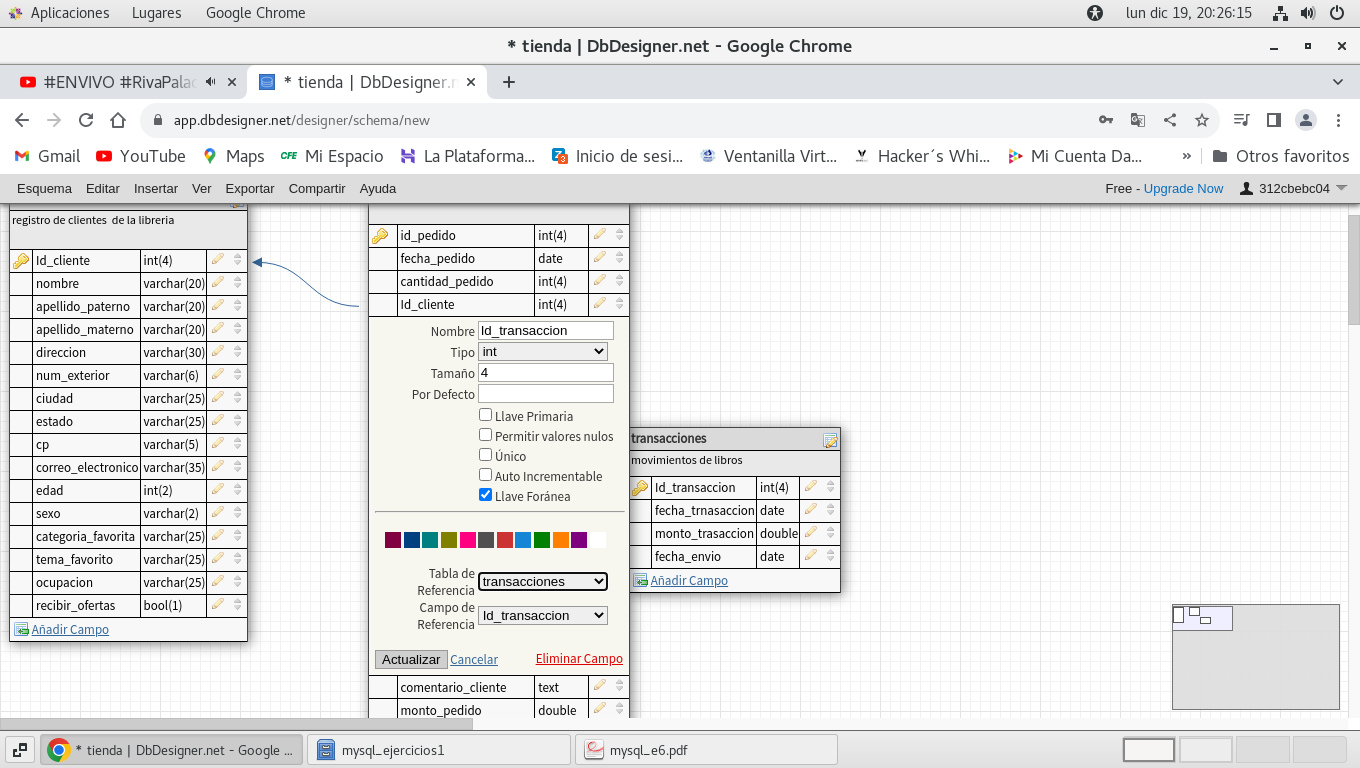
en la parte inferior del cuadro de
dialogo están de nuevo los conceptos de Tabla de Referencia y
Campo de Referencia, que deben de ubicarse con la tabla
transacciones, y el campo Id_transaccion, editamos el
campo y le asignamos llave foránea, y clic en Actualizar, con
ello se conectaran ambas tablas.
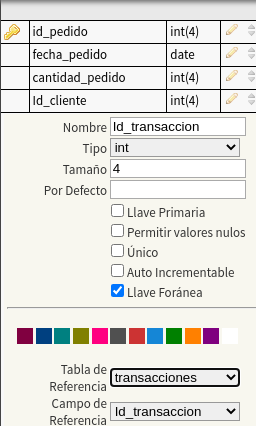
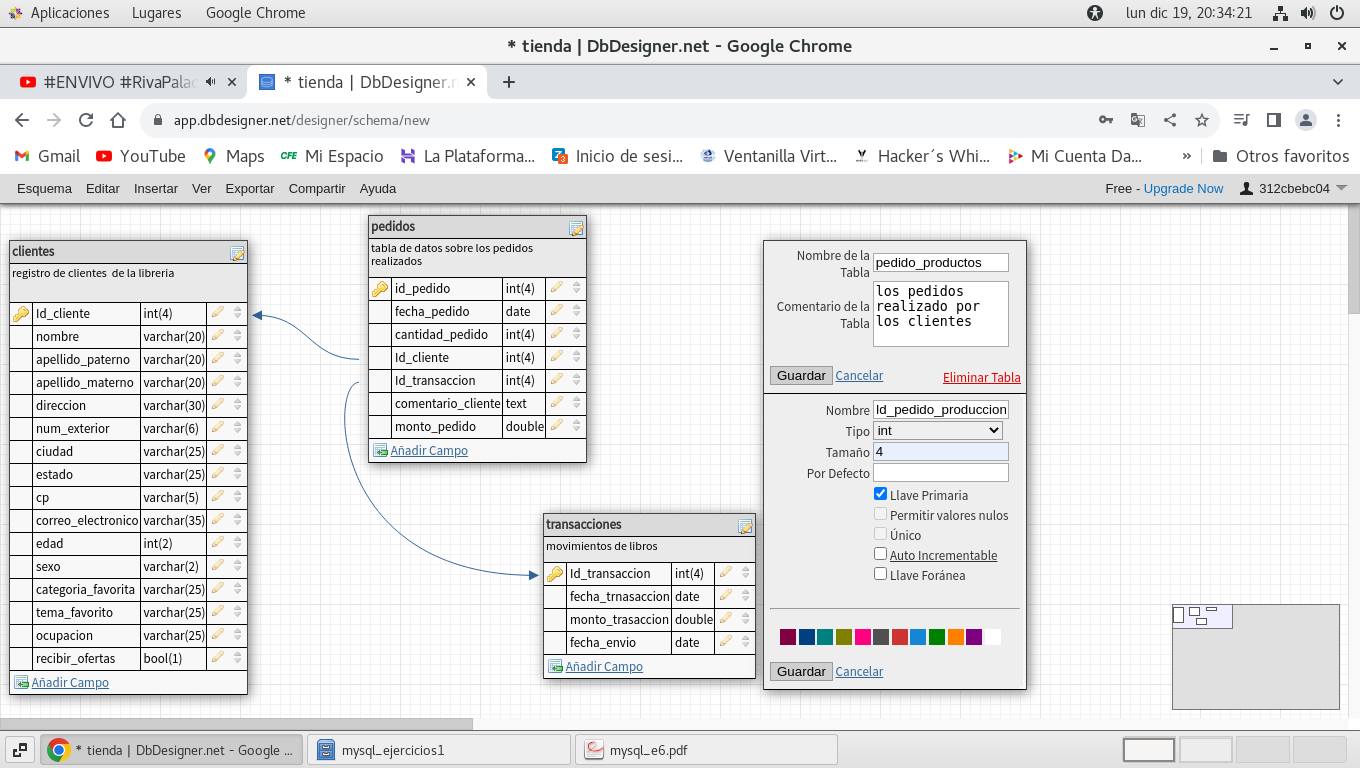
definimos la tabla pedido_productos, que tiene una clave
primaria, Id_pedido_produccion
designamos la clave foránea, relacionando la tabla
pedido_productos, a la tabla pedidos, con el campo id_pedido:
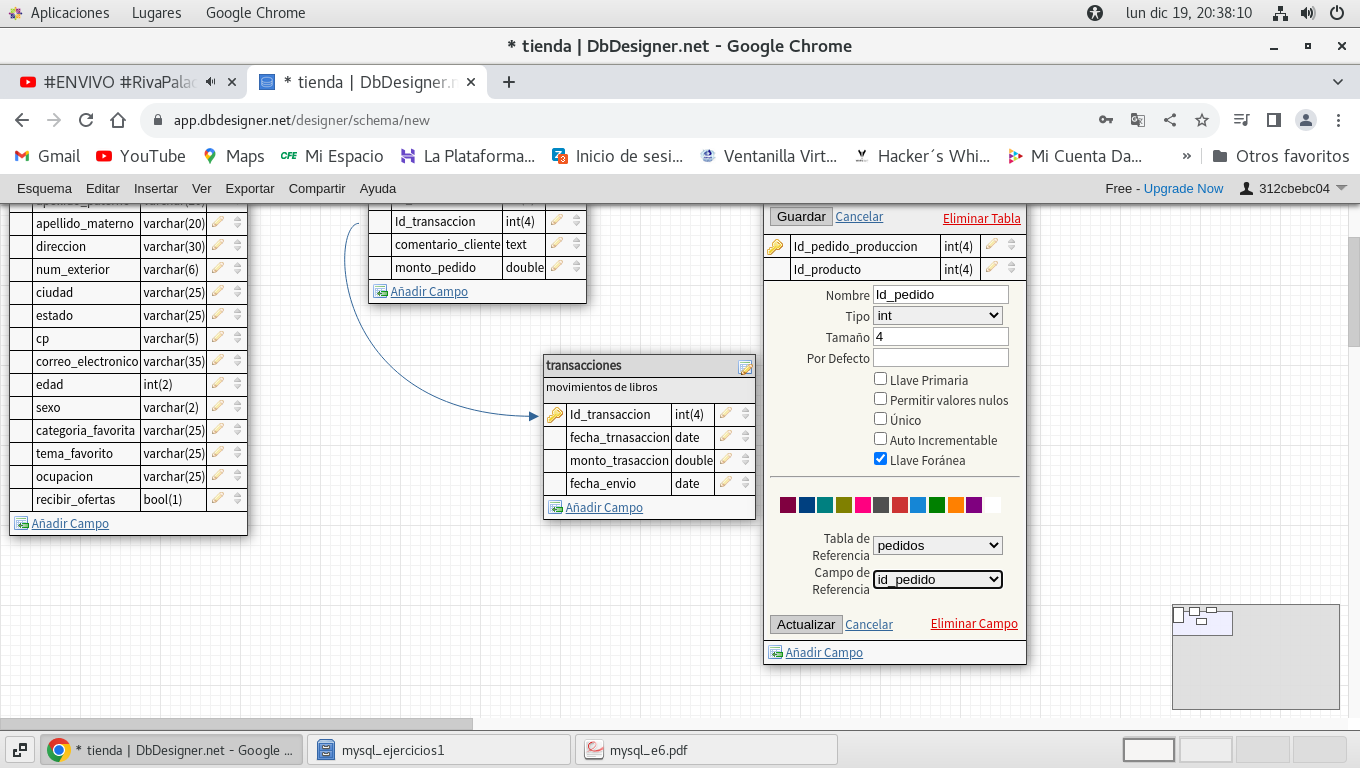
igual que en los casos anteriores se
observa la relacion que debe de existir entre esta tabla y la de
pedidos, y el campo id_pedido
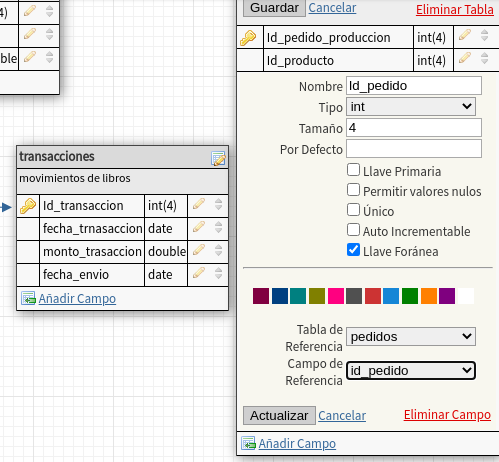
quedando así:
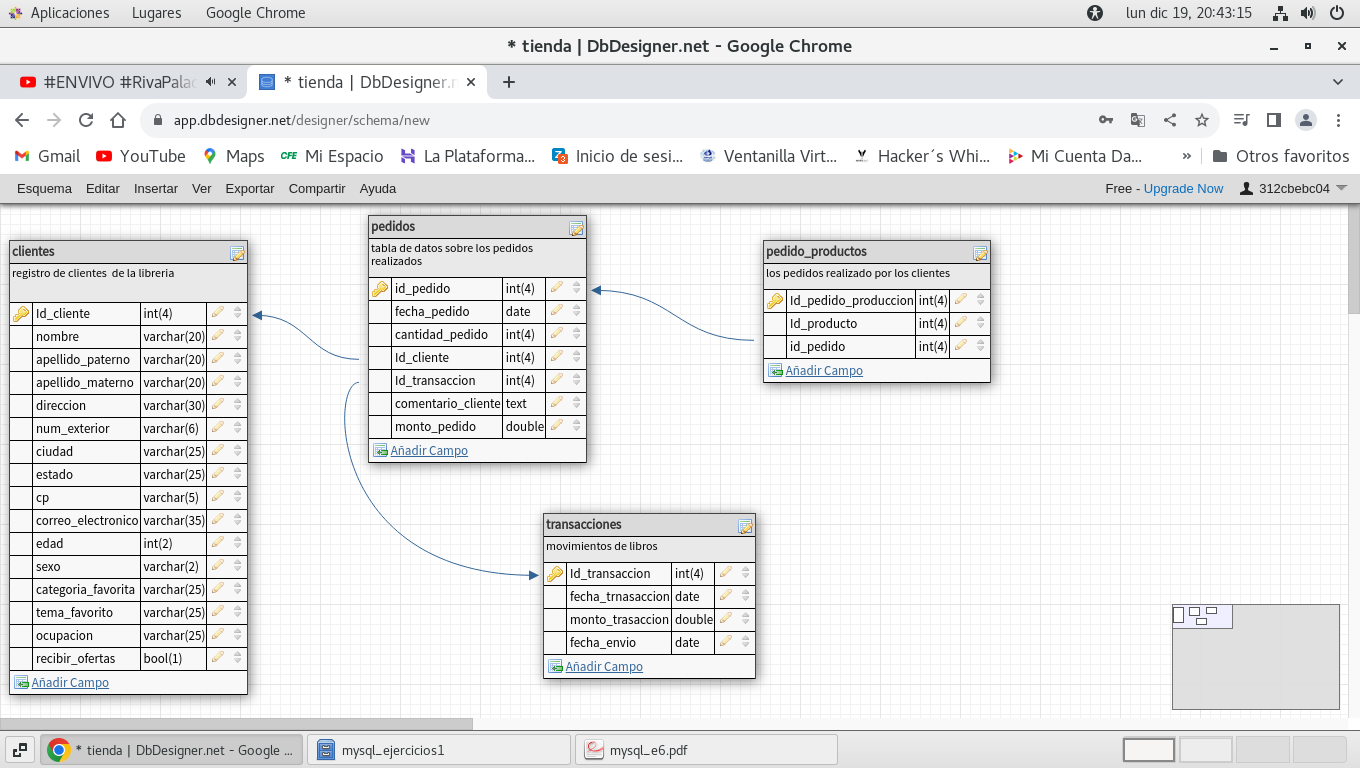
tabla productos con clave primaria, Id_producto
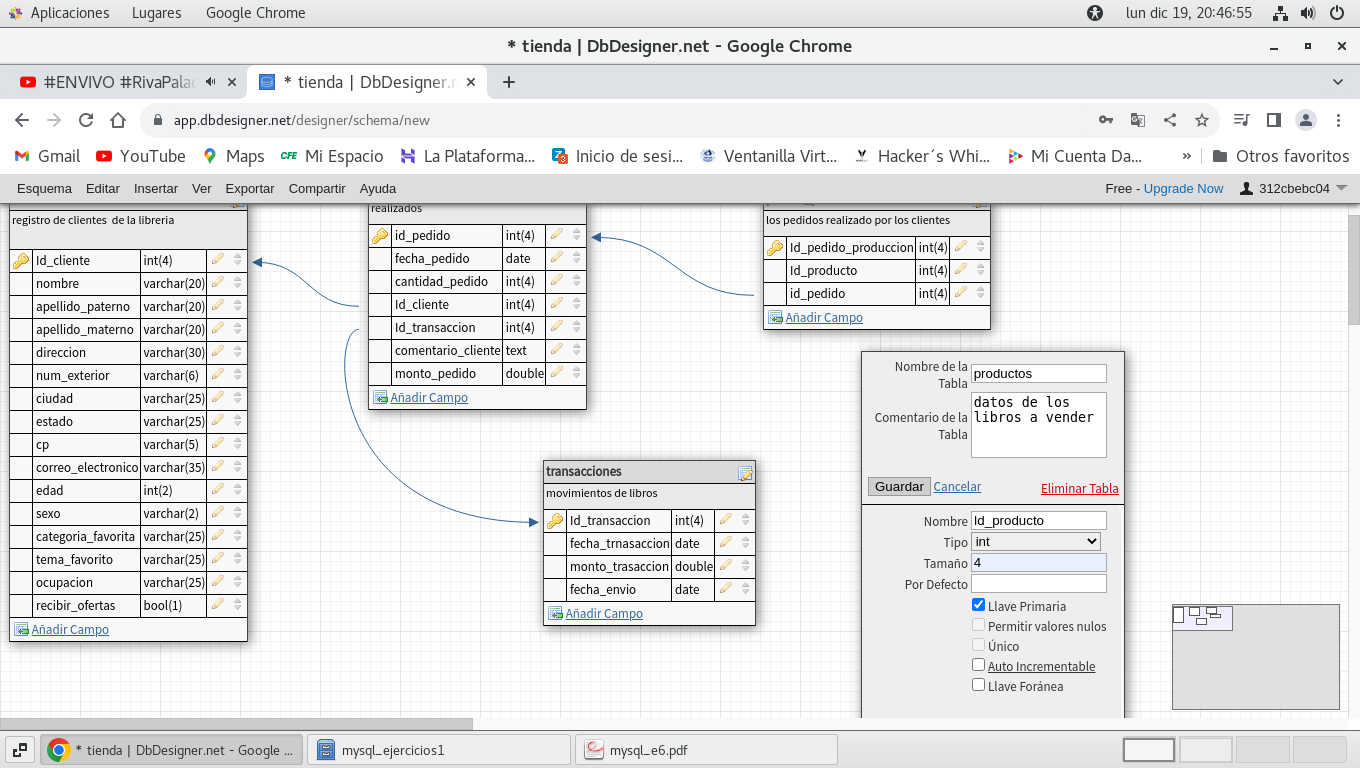
quedando así la tabla
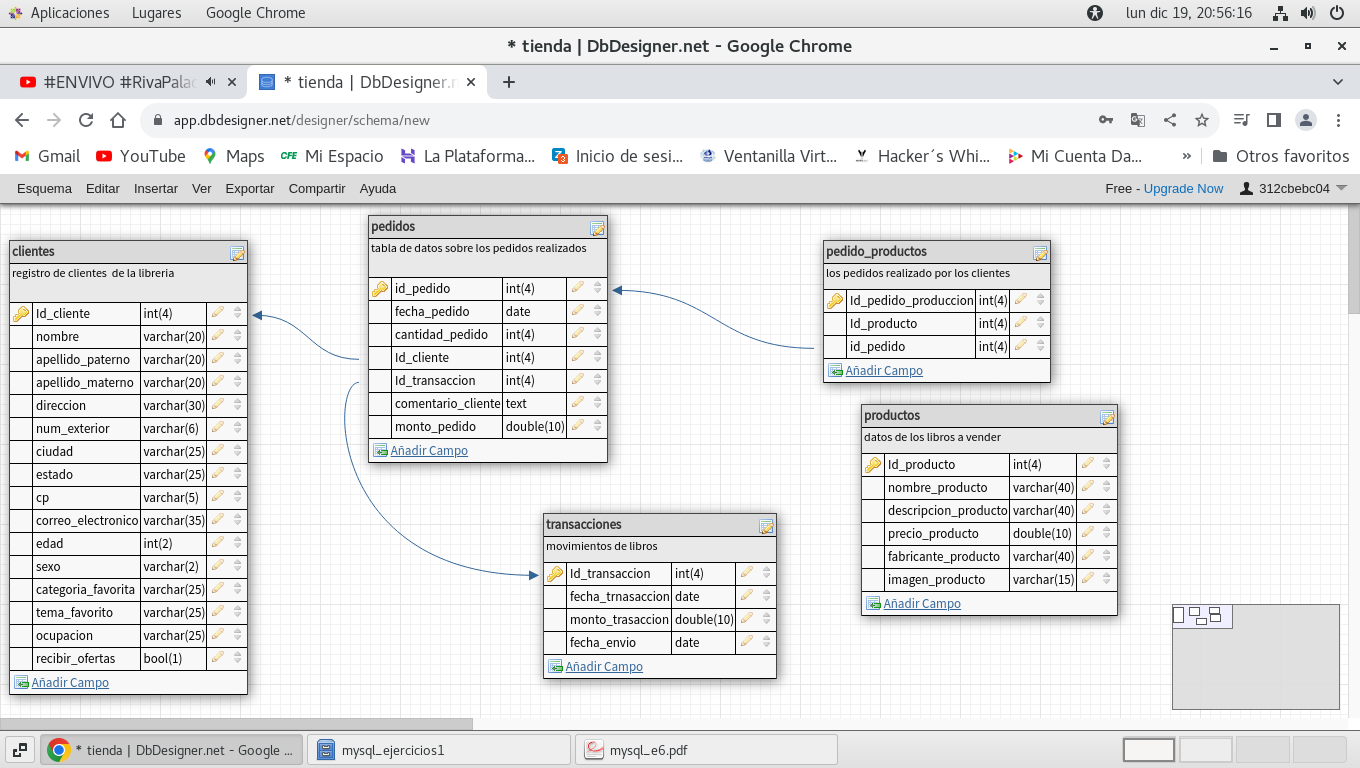
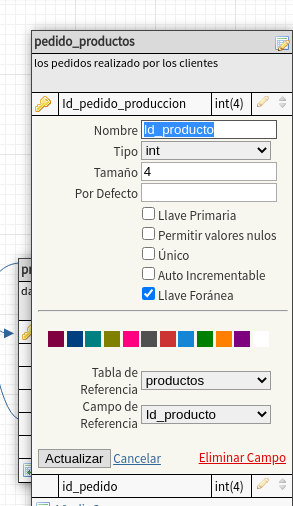
modificamos pedidos_productos, el campo Id_producto para ser
clave foránea
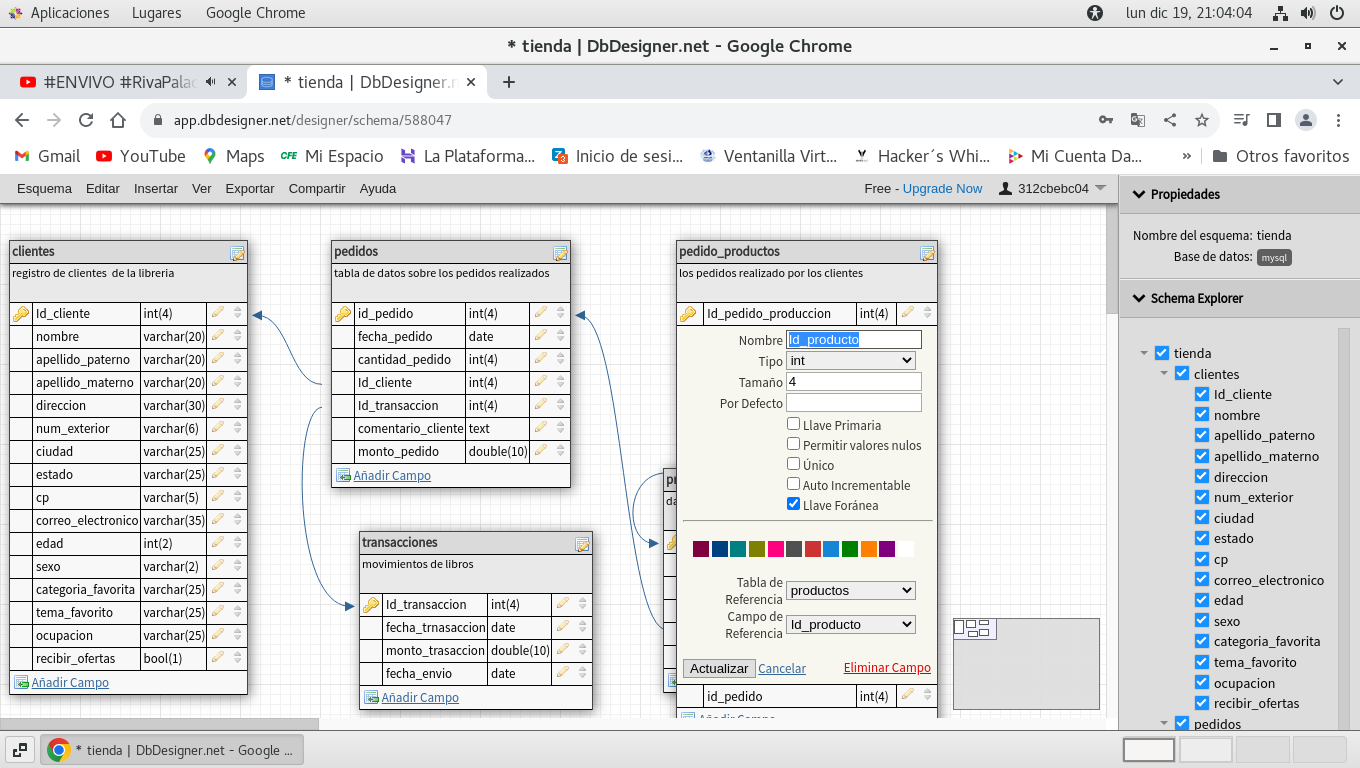
igual que en los casos anteriores se
observa la relacion que debe de existir entre esta tabla y la de
productos, y el campo Id_producto
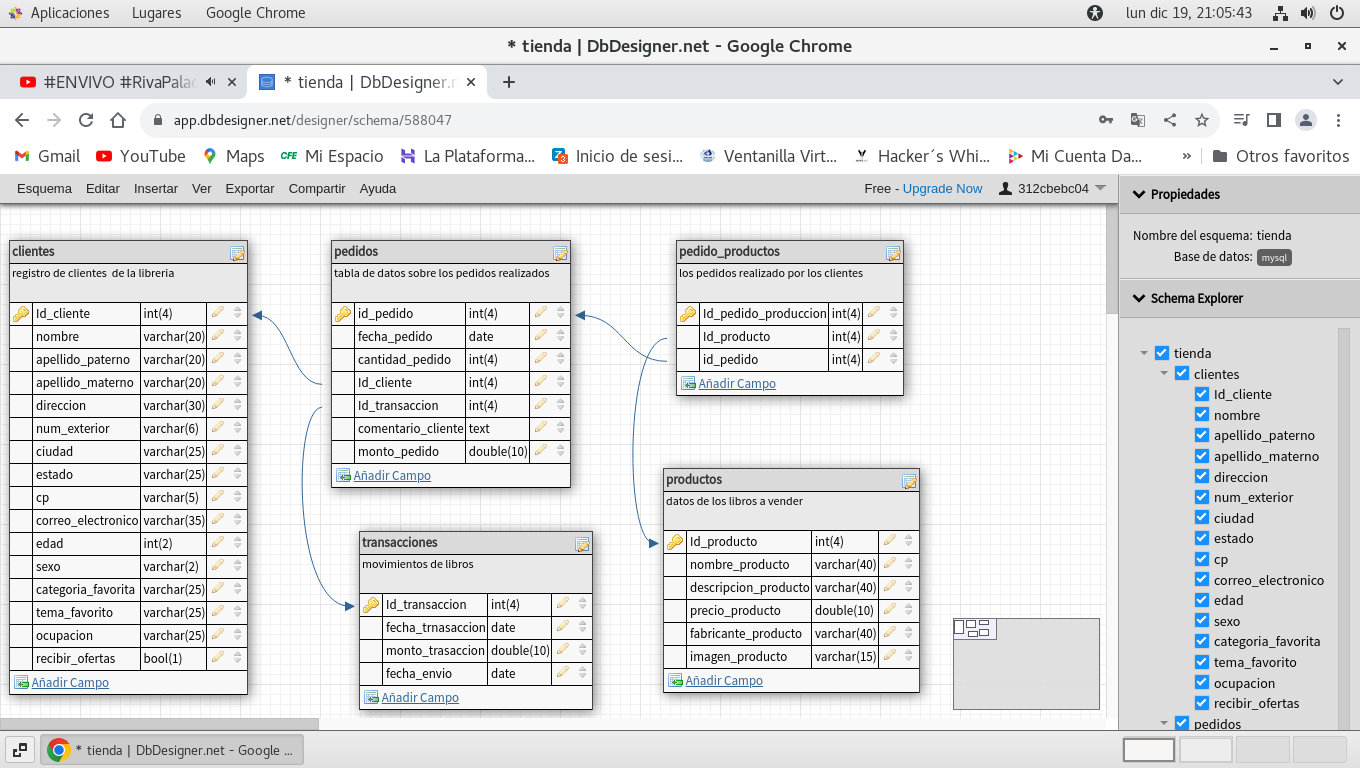
asi quedaran las tablas en la base de datos
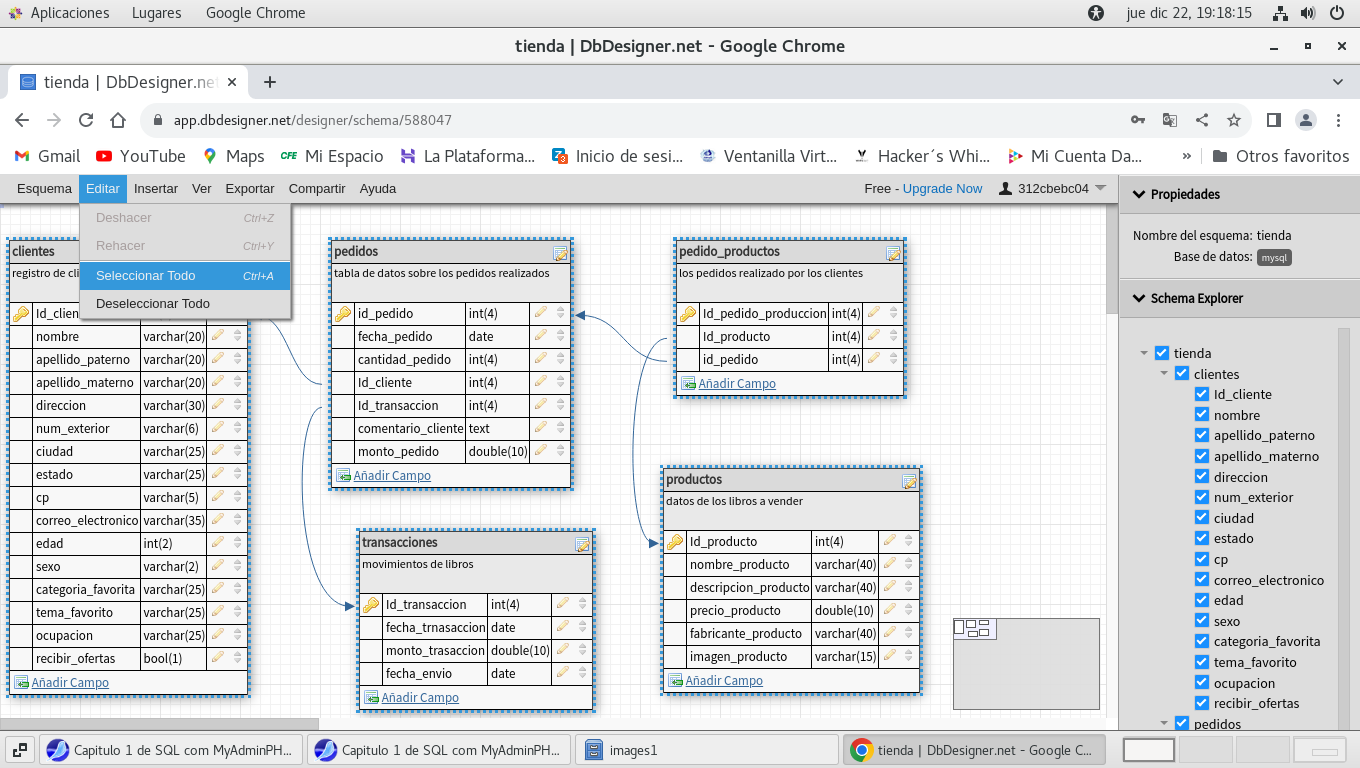
el siguiente paso es exportar todas las tablas a un script para
ejecutarlo en PhpMyAdmin, ya que escribir campo a campo y sus
características seria muy tardado y podríamos equivocarnos al
verlos en forma de texto , así que, en el esquemas usamos el menu
Editar, Seleccionar todo:
y exportamos todas las tablas para un script de SQL..
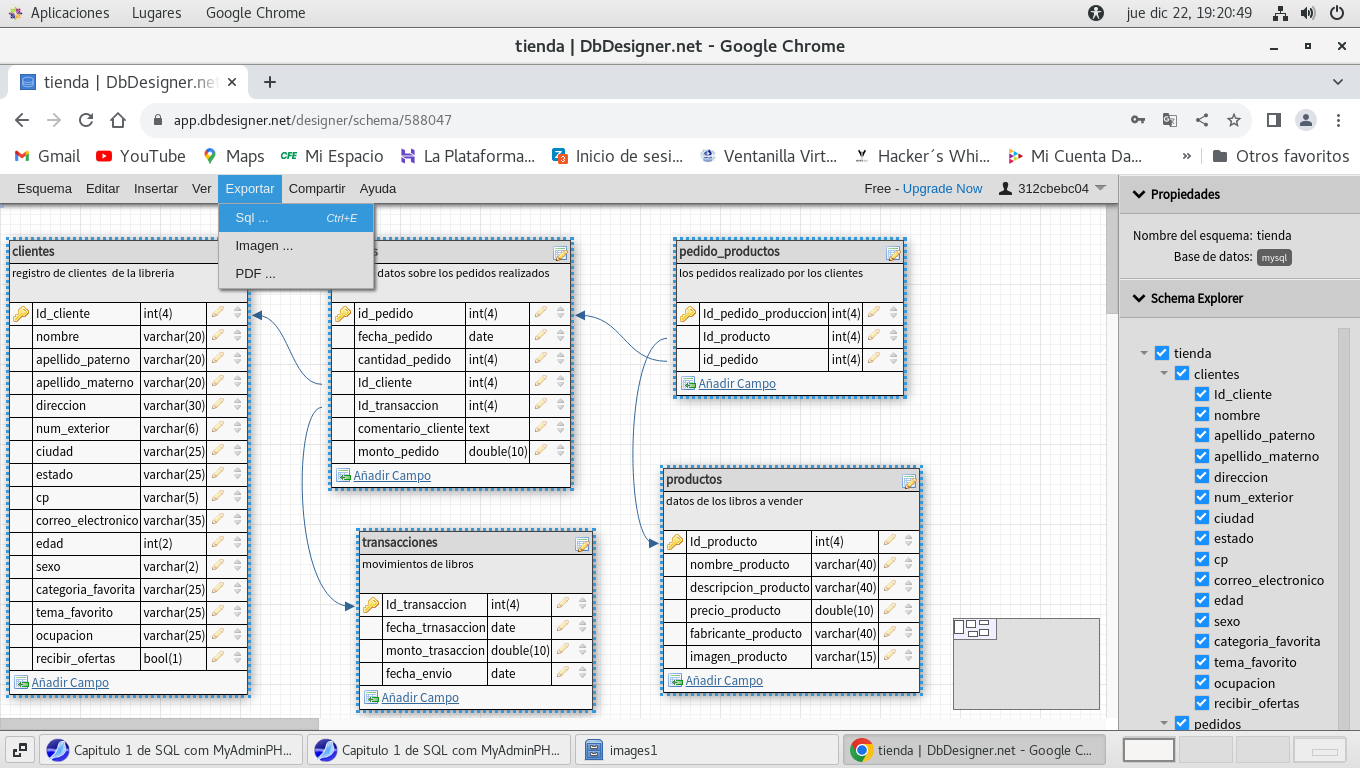
Clic en Exportar SQL
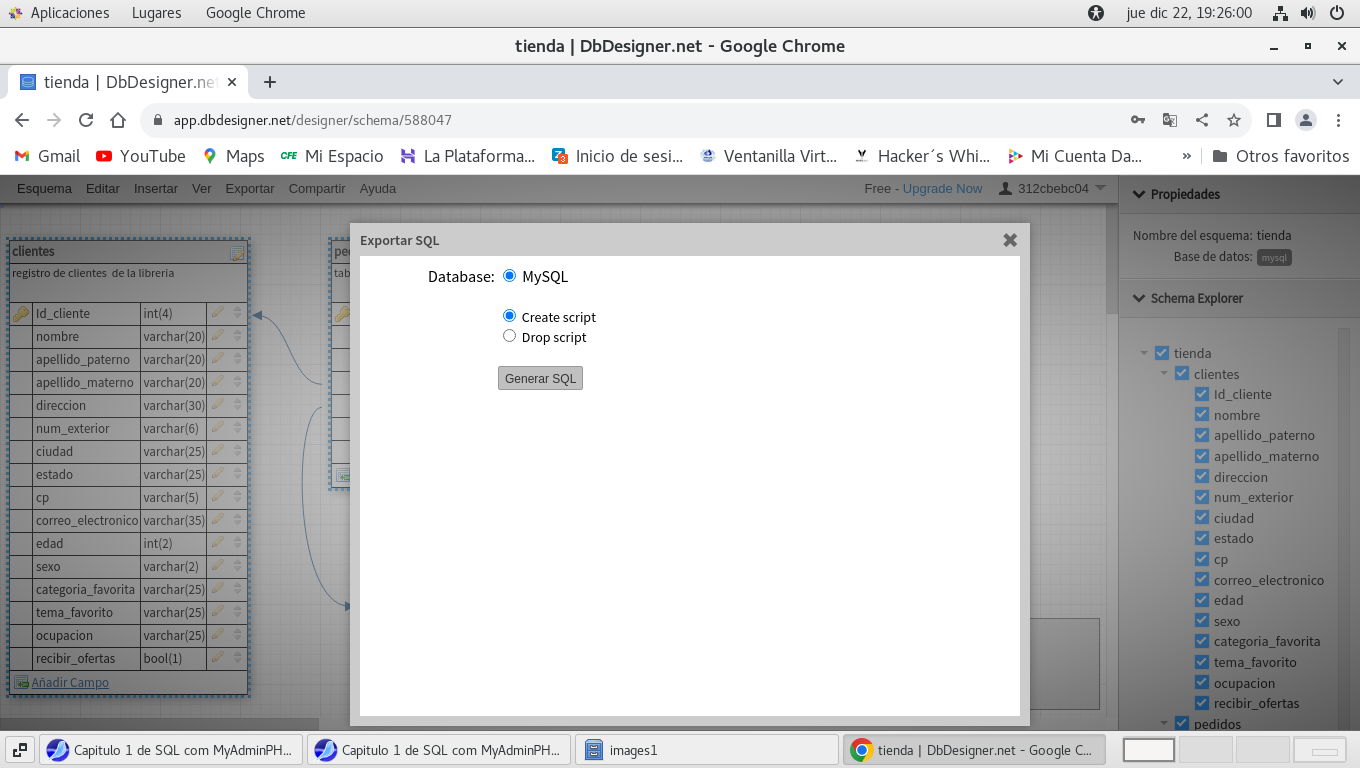
Supongamos ahora que ya casi estamos listos para
pasar nuestro script, a PhpMyAdmin, y nos piden cambios en algunos
de las campos de las tablas:
1) Los campos de numéricos de double los
tenemos que modificar a float, por la precisión de datos
numéricos a usar, adicionalmente son campos que son para
almacenar datos numéricos muy grandes que no necesitamos en este
momento, ocupan mucho espacio y son requeridos, por esa razón
los cambiamos a float.
2) El campo de clientes recibir_ofertas puede ser mas de un solo
valor puede tener hasta 5 valores diferentes, así que el valor
de bool (boleano) no es el adecuado para nuestro caso, puesto
que solo recibe falso o verdadero, por lo que lo cambiamos a
char(1).
por lo que se deberá verse asi:
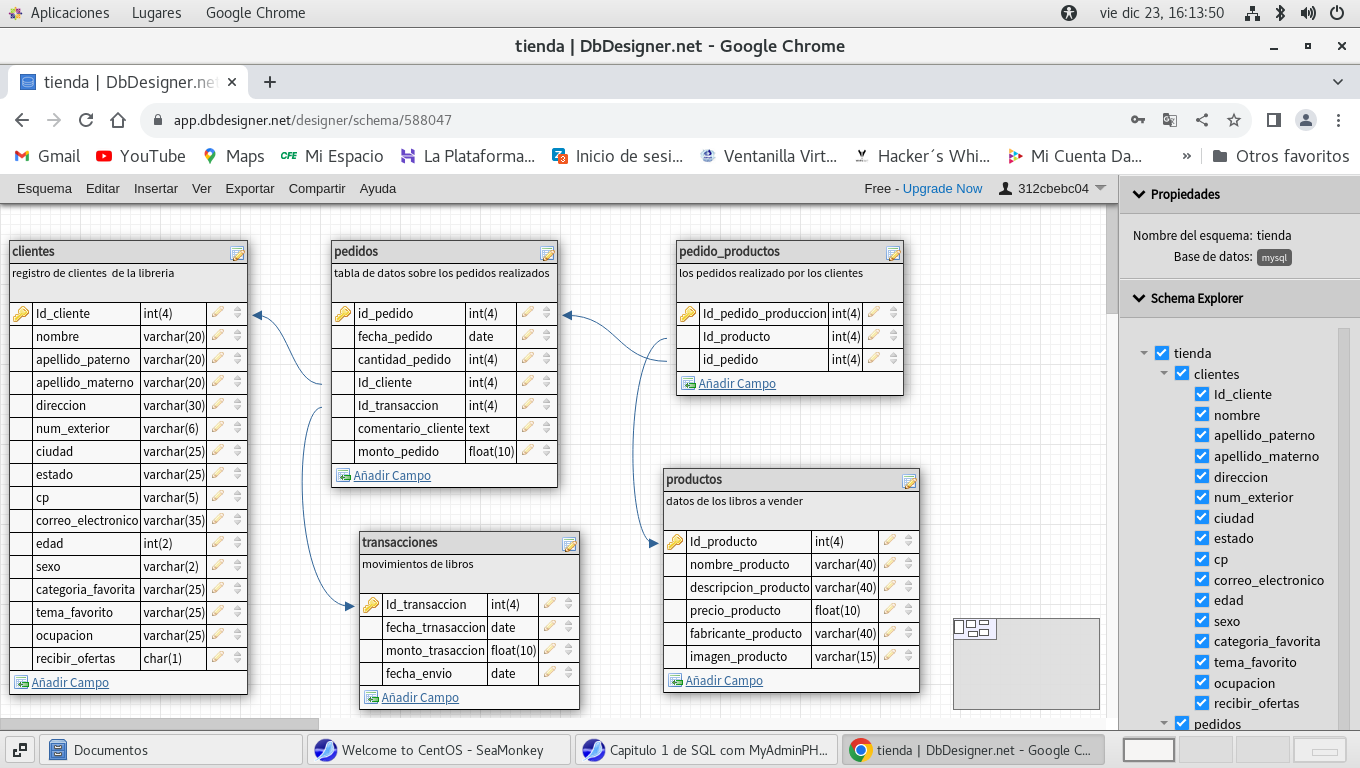
así que debemos de modificar las tablas, en la
tabla clientes, transacciones, productos y pedidos, esto lo
realizamos con el icono que tiene la figura de lápiz, en el campo
a modificar, los alumnos deberán de terminar de cambiar el
resto de los campos, ya realizados los cambios a las tablas,
se vuelve a exportar el nuevo script, esto que se realizo, es muy
frecuente que se presente, esto se debe a que las personas que se
entrevistan cambian de opinión, y desean cambiar o agregar algo
mas que no habían considerando, o quieren mejorar, por eso es
importante que los desarrolladores hagan aclaraciones antes de
creación de programas o diseños, si ya se estableció de común
acuerdo programador - cliente, cualquier cambio deberá de agregar
costo adicional porque podría poner mas tiempo a los cambios,
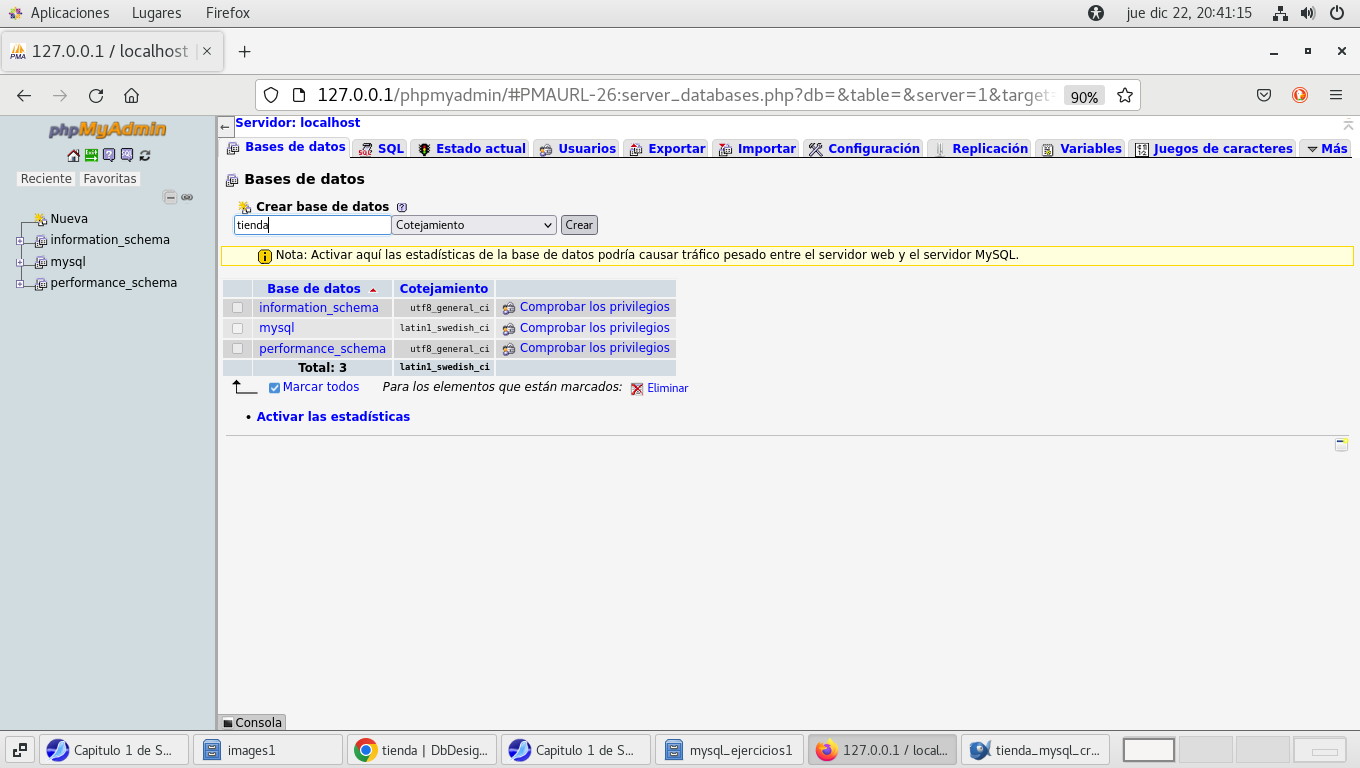
después de considerar esto, procedemos a crear la base de datos en
PhpMyAdmin :
y descargamos el script, que formamos en
https://app.dbdesigner.net/ ,y en el script se mostraran las
tablas y los campos llave primaria en la parte superior del
script, y la llave foranea al final del script, es importante que
anotes estos pasos, ya que primero generamos las tablas y luego al
final de cada tabla sus llaves primarias, y al final del script
las llaves foraneas, vea que se usa el comando ALTER TABLE (13), que significa que se modificara la
tabla , y el comando ADD CONSTRAINT (14)
se utiliza junto con ALTER TABLE para agregar restricciones (como
una clave principal o una clave externa) a una tabla existente en
una base de datos SQL.
el script es el siguiente:
CREATE TABLE `clientes` (
`Id_cliente` int(4) NOT NULL,
`nombre` varchar(20) NOT NULL,
`apellido_paterno` varchar(20) NOT NULL,
`apellido_materno` varchar(20) NOT NULL,
`direccion` varchar(30) NOT NULL,
`num_exterior` varchar(6) NOT NULL,
`ciudad` varchar(25) NOT NULL,
`estado` varchar(25) NOT NULL,
`cp` varchar(5) NOT NULL,
`correo_electronico` varchar(35) NOT NULL,
`edad` int(2) NOT NULL,
`sexo` varchar(2) NOT NULL,
`categoria_favorita` varchar(25) NOT NULL,
`tema_favorito` varchar(25) NOT NULL,
`ocupacion` varchar(25) NOT NULL,
`recibir_ofertas` char(1) NOT NULL,
PRIMARY KEY (`Id_cliente`)
);
CREATE TABLE `pedidos` (
`id_pedido` int(4) NOT NULL,
`fecha_pedido` DATE NOT NULL,
`cantidad_pedido` int(4) NOT NULL,
`Id_cliente` int(4) NOT NULL,
`Id_transaccion` int(4) NOT NULL,
`comentario_cliente` TEXT NOT NULL,
`monto_pedido` FLOAT(10) NOT NULL,
PRIMARY KEY (`id_pedido`)
);
CREATE TABLE `transacciones` (
`Id_transaccion` int(4) NOT NULL,
`fecha_trnasaccion` DATE NOT NULL,
`monto_trasaccion` FLOAT(10) NOT NULL,
`fecha_envio` DATE NOT NULL,
PRIMARY KEY (`Id_transaccion`)
);
CREATE TABLE `pedido_productos` (
`Id_pedido_produccion` int(4) NOT NULL,
`Id_producto` int(4) NOT NULL,
`id_pedido` int(4) NOT NULL,
PRIMARY KEY (`Id_pedido_produccion`)
);
CREATE TABLE `productos` (
`Id_producto` int(4) NOT NULL,
`nombre_producto` varchar(40) NOT NULL,
`descripcion_producto` varchar(40) NOT NULL,
`precio_producto` FLOAT(10) NOT NULL,
`fabricante_producto` varchar(40) NOT NULL,
`imagen_producto` varchar(15) NOT NULL,
PRIMARY KEY (`Id_producto`)
);
ALTER TABLE `pedidos` ADD CONSTRAINT `pedidos_fk0` FOREIGN KEY
(`Id_cliente`) REFERENCES `clientes`(`Id_cliente`);
ALTER TABLE `pedidos` ADD CONSTRAINT `pedidos_fk1` FOREIGN KEY
(`Id_transaccion`) REFERENCES `transacciones`(`Id_transaccion`);
ALTER TABLE `pedido_productos` ADD CONSTRAINT `pedido_productos_fk0`
FOREIGN KEY (`Id_producto`) REFERENCES `productos`(`Id_producto`);
ALTER TABLE `pedido_productos` ADD CONSTRAINT `pedido_productos_fk1`
FOREIGN KEY (`id_pedido`) REFERENCES `pedidos`(`id_pedido`);
pasamos a la etiqueta o pestaña SQL, abrimos el
escript creado en los pasos anteriores, debes de localizarlo en el
directorio donde lo descargaste, lo copiamos con el editor de
textos que tu decidas yo lo abro con la aplicacion llamada
BlueFish pero cualquier editor se puede usar.
Abajo se ve el procesador llamado BlueFish.
pegamos el script en el área de SQL para
ejecutar el script y clic en el botón Continuar.
si no hay errores se debera de ver de esta manera:
cuando veamos ese recuadro verde es que se realizo de forma
correcta el script y en la etiqueta Estructura, veremos que son
las tablas de la base de datos:
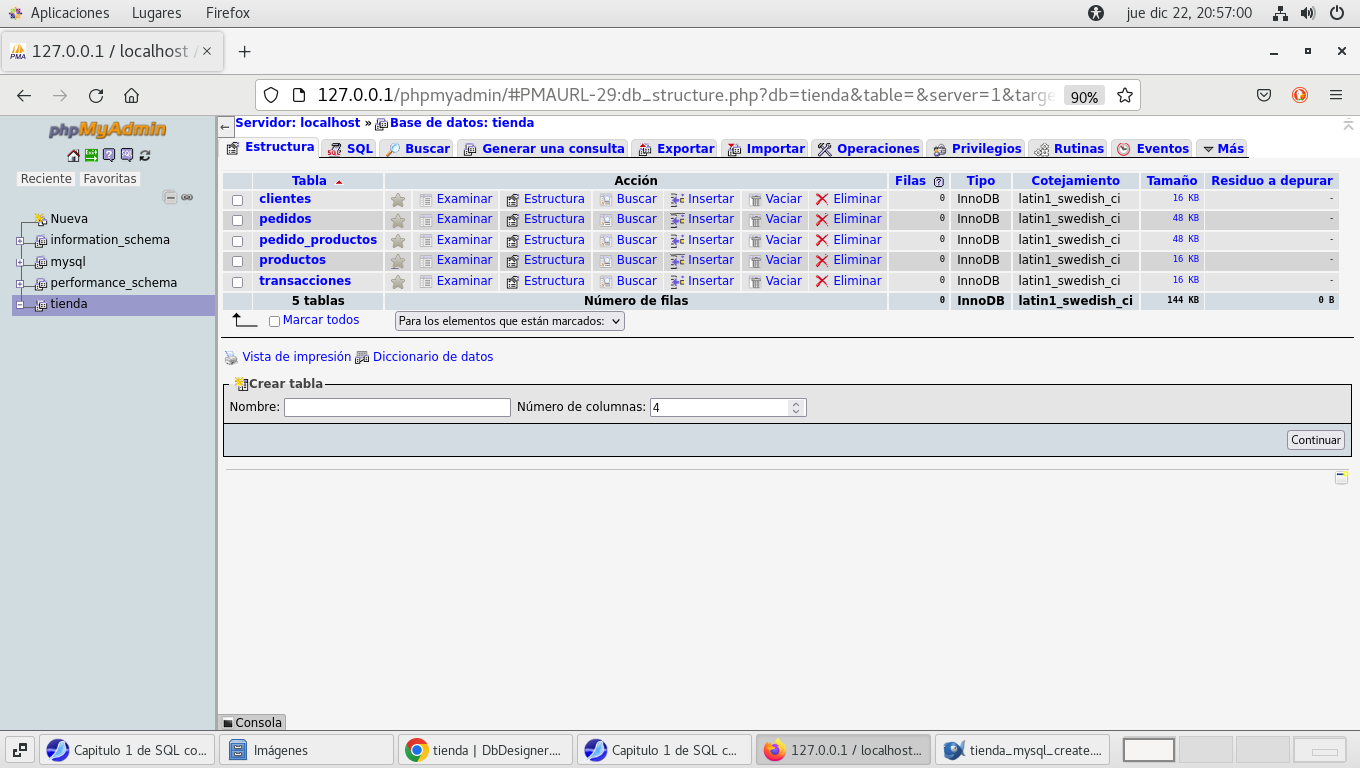
del lado izquierdo del panel, observamos un
área de color diferente, y si hacemos clic en tienda veremos las
tablas que forman la base de datos.
al hacer clic en una tabla por ejemplo clientes
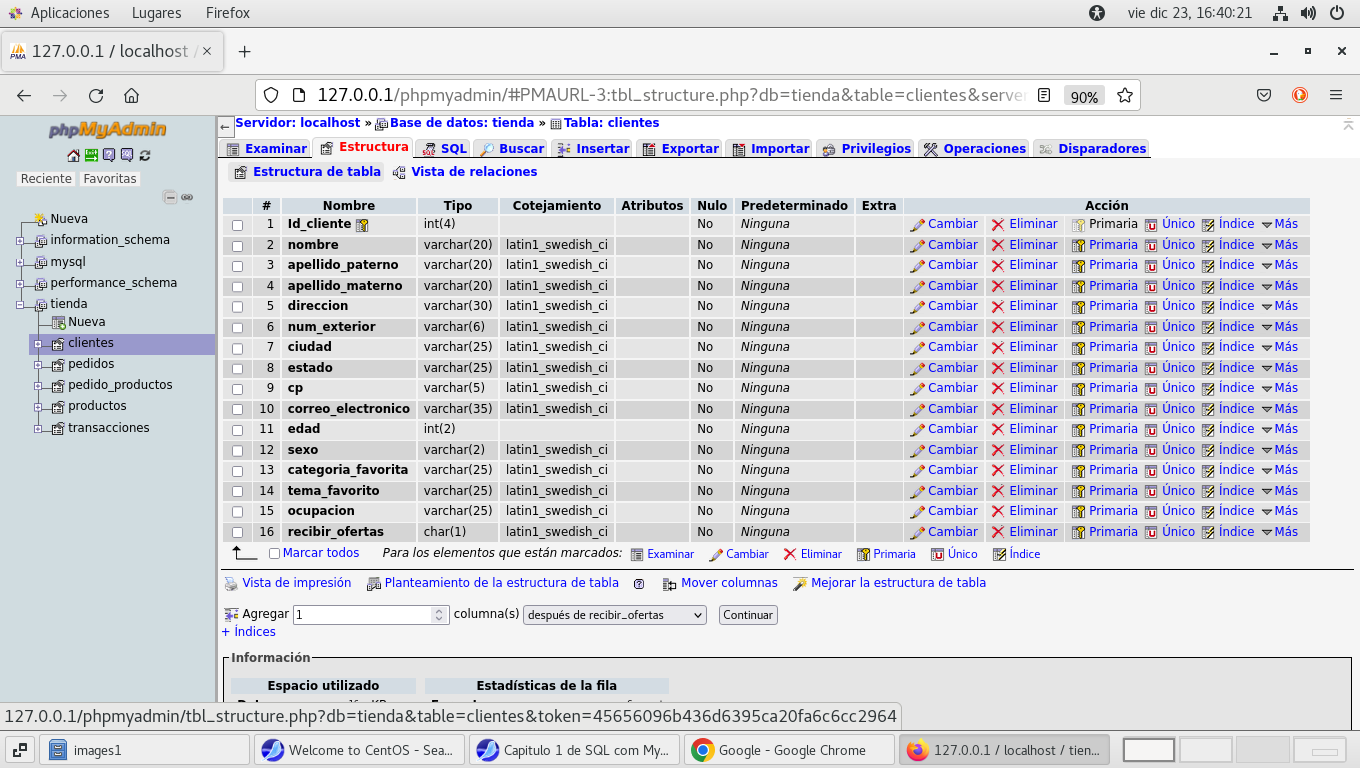
y en las pestañas del lado derecho seleccionamos estructura,
veremos todos los campos de la tabla, y si observamos del lado
derecho dice Acción y y una columna Primaria (llave primaria,
Primary key) el icono se ve mas opaco indica que este campo
tiene una clave primaria y del lado del nombre del campo esta el
mismo icono que indica esa llave primaria:
hay algo interesante en PhpMyAdmin, podemos ver
la relacion de las bases de datos en un apartado especial de
PhpMyAdmin, para que se logre apreciar se debera de configurar
correctamente los parámetros de PhpMyAdmin, como se vio
inicialmente en la unidad de Gestión de sistemas operativos
y virtualización observe el siguiente video
, donde se puede apreciar la ventajas del diseñador de PhpMyAdmin.
de hecho podemos crear aquí el diseño pero por
un lado es cómodo hacerlo en una aplicación diferente para no
tener que estar cambiando constantemente las tablas desde
PhpMyAdmin, y poderlo apreciar desde otro punto de vista
dbdesigner es buena herramienta para elaborar estos scripts para
SQL.
seleccione en la parte izquierda la base de datos: tienda
y del lado derecho vemos lo siguiente:
y en particular esta parte de titulo Tipo:
Revisemos que es esto, InnoDB (15) es un mecanismo de almacenamiento de
datos de código abierto para la base de datos MySQL, incluido como
formato de tabla estándar en todas las distribuciones de MySQL a
partir de las versiones 4.0, es mas lento que su antesesor MyISAM,
(Indexed Sequential Access Method)
pero es muy seguro los procesos rollback son mas confiables. Su
característica principal es que soporta transacciones de tipo ACID
(Atomicity, Consistency,
Isolation and Durability:
Atomicidad, Consistencia,
Aislamiento y Durabilidad)
y bloqueo de registros e integridad referencial. InnoDB ofrece una
fiabilidad y consistencia muy superior a MyISAM,(Método de Acceso
Secuencial Indexado), muy rápido pero si hay alguna falla es muy
difícil recuperar los datos de la tabla, la anterior tecnología de
tablas de MySQL, si bien el mejor rendimiento de uno u otro
formato dependerá de la aplicación, pero de preferencia usar
InnoDB.
Al poder gestionar bases de datos relacionales,
InnoDB soporta FOREIGN KEY, mientras que MyISAM es incapaz de
gestionarlos.
InnoDB almacena sus tablas e índices en un
espacio de tablas que puede estar formado de varios ficheros o
varias particiones. Por el contrario cada tabla MyISAM almacenada
en disco genera tres ficheros con el mismo nombre, que será el
nombre de la tabla, pero diferentes extensiones. Un fichero .frm
donde se guarda la estructura de la tabla, un fichero .myd donde
se guardan los datos de la tabla y un fichero .myi donde se
guardan los índices de la tabla.
MyISAM permite la indexación de campos de tipo
blob y text, al igual que permite valores nulos en columnas
indexadas, mientras que InnoDB no. Por tanto si en su aplicación
es necesario realizar búsquedas full-text, necesitará una base de
datos MyISAM.
MyISAM es más rápido que InnoDB, puesto que en las consultas
InnoDB se debe de comprobar la integridad referencial de los
datos, mientras que en MyISAM eso no es necesario, ya que esa
propiedad no es soportada por este motor de almacenamiento.
InnoDB disponde de herramientas de recuperación ante errores o
reinicios inesperados del sistema a partir de sus logs, mientras
que MyISAM necesita una exploración exhaustiva para encontrar los
índices de los datos de las tablas y recuperarlos en el caso de
que los datos no hayan sido volcados todavía a disco.
Si deseamos crear una tabla utilizando un motor en particular,
debemos seguir la siguiente estructura.(16)
CREATE TABLE tabla_innodb (id int, value int) ENGINE=INNODB;
CREATE TABLE tabla_myisam (id int, value int) ENGINE=MYISAM;
podemos hacer cambios en nuestras tablas ya que
se han creado, por ejemplo el campo sexo, recordemos que una de
las condiciones de la tienda es que solo deben ser Hombre o Mujer,
por lo que podemos hacer cambios en este campo, de la tabla
clientes, esta marcado el campo y hacemos clic en cambiar :
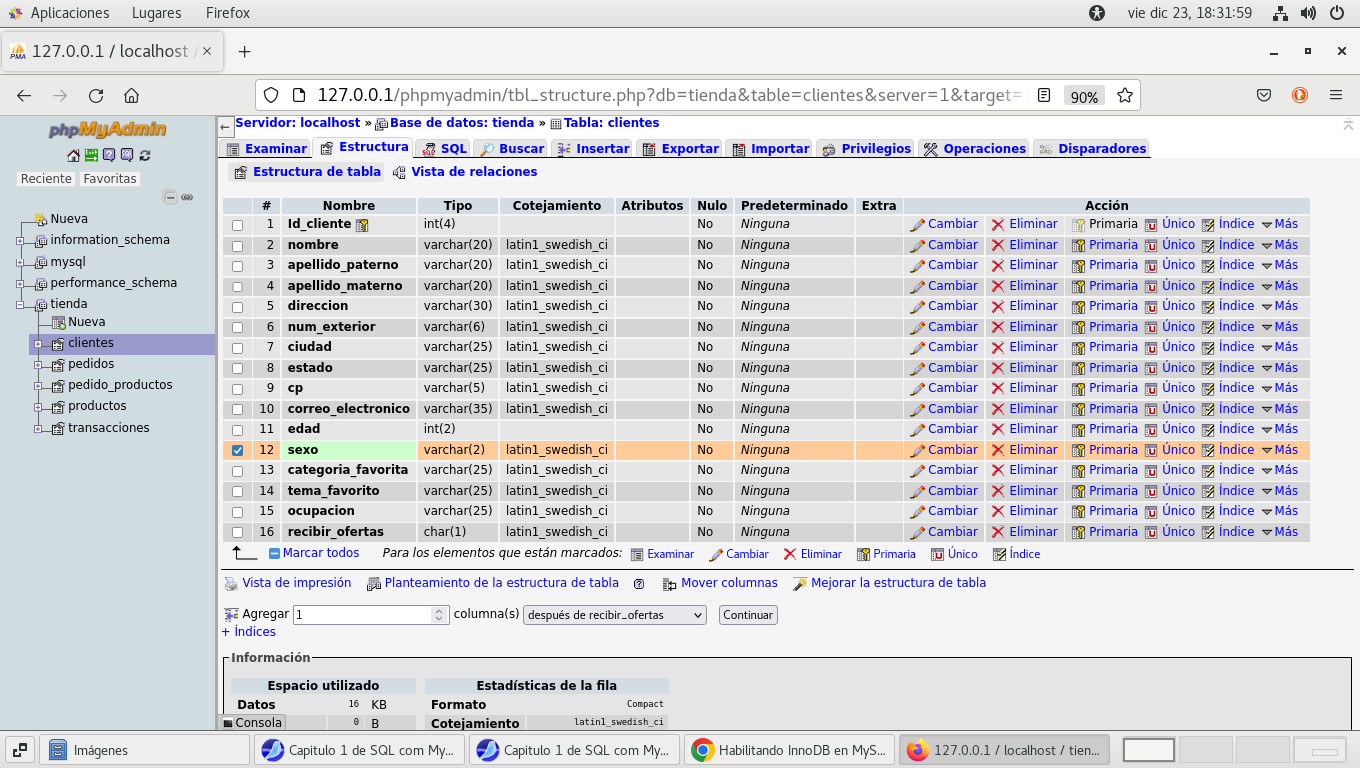
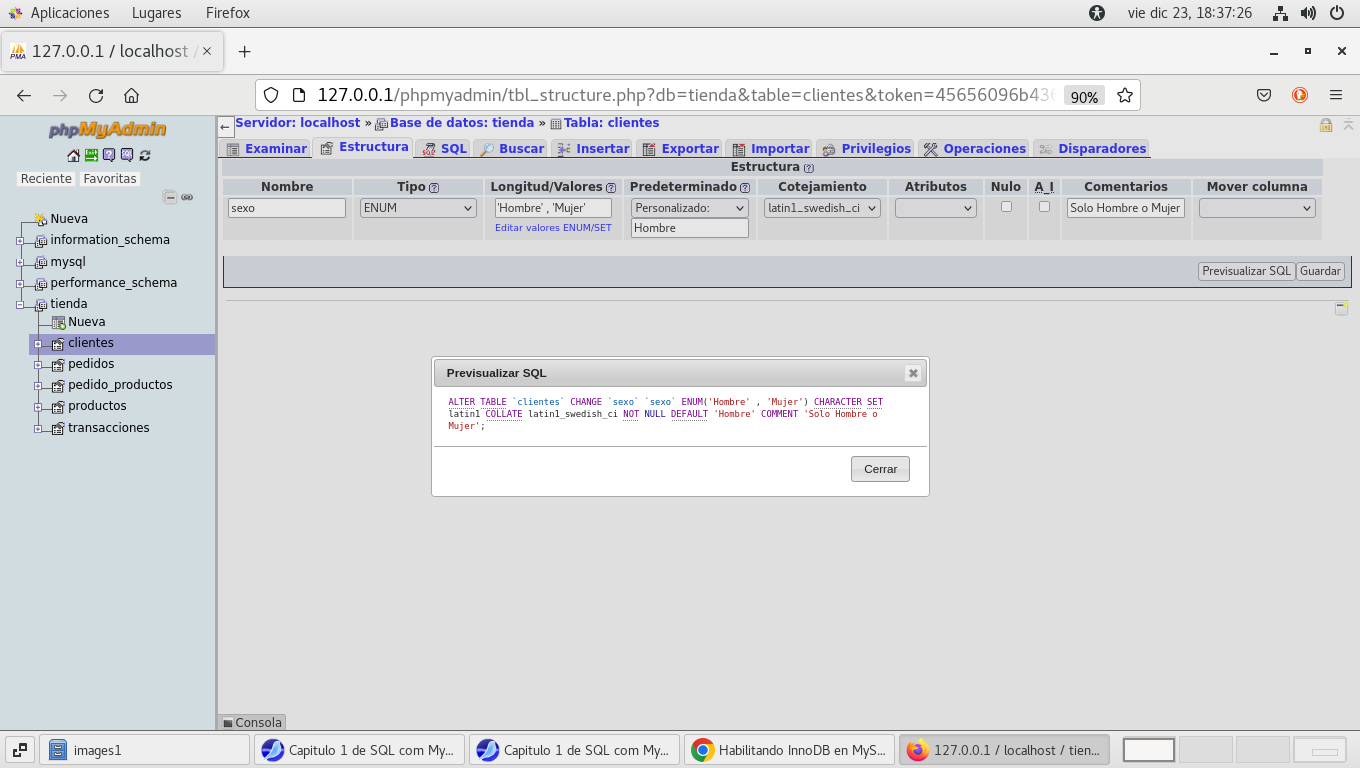
modificamos las propiedades del campo, Tipo lo
pasamos a ENUM (Enumerar), esto consiste en una lista enumerada,
significa que solo puede almacenar uno de los valores declarados
en la lista, puede tener hasta 65,535 elementos de la lista, estos
campos son muy útiles cuando se usan en las paginas
web. Los datos deberán estar como 'Hombre','Mujer' que son
las dos posibles opciones unicamente, y en el de Predeterminado
seleccionamos Personalizado, y por default se asigna Hombre, en
cuanto llegamos al campo cuando capturemos, previsualizamos SQL:
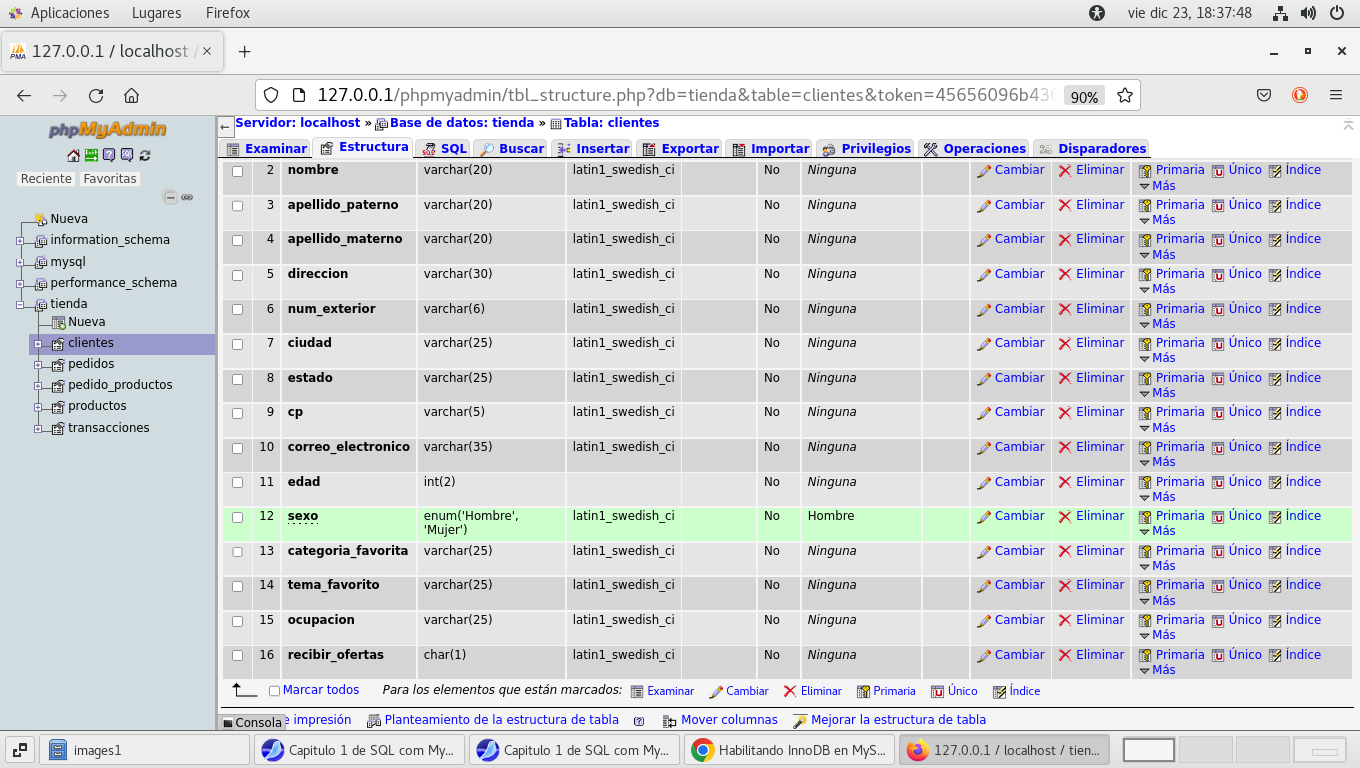
aplicamos el botón Guardar y se ejecuta el comando, y el
resultado es:
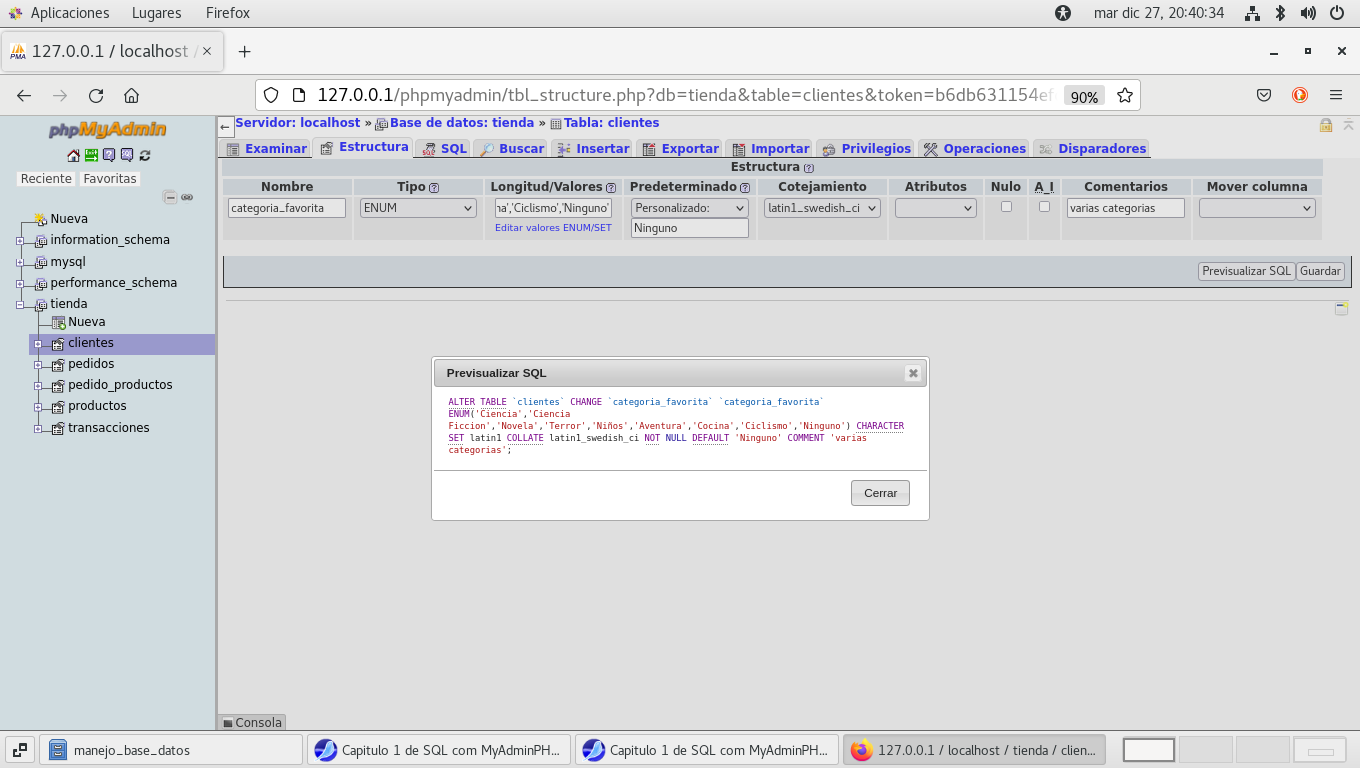
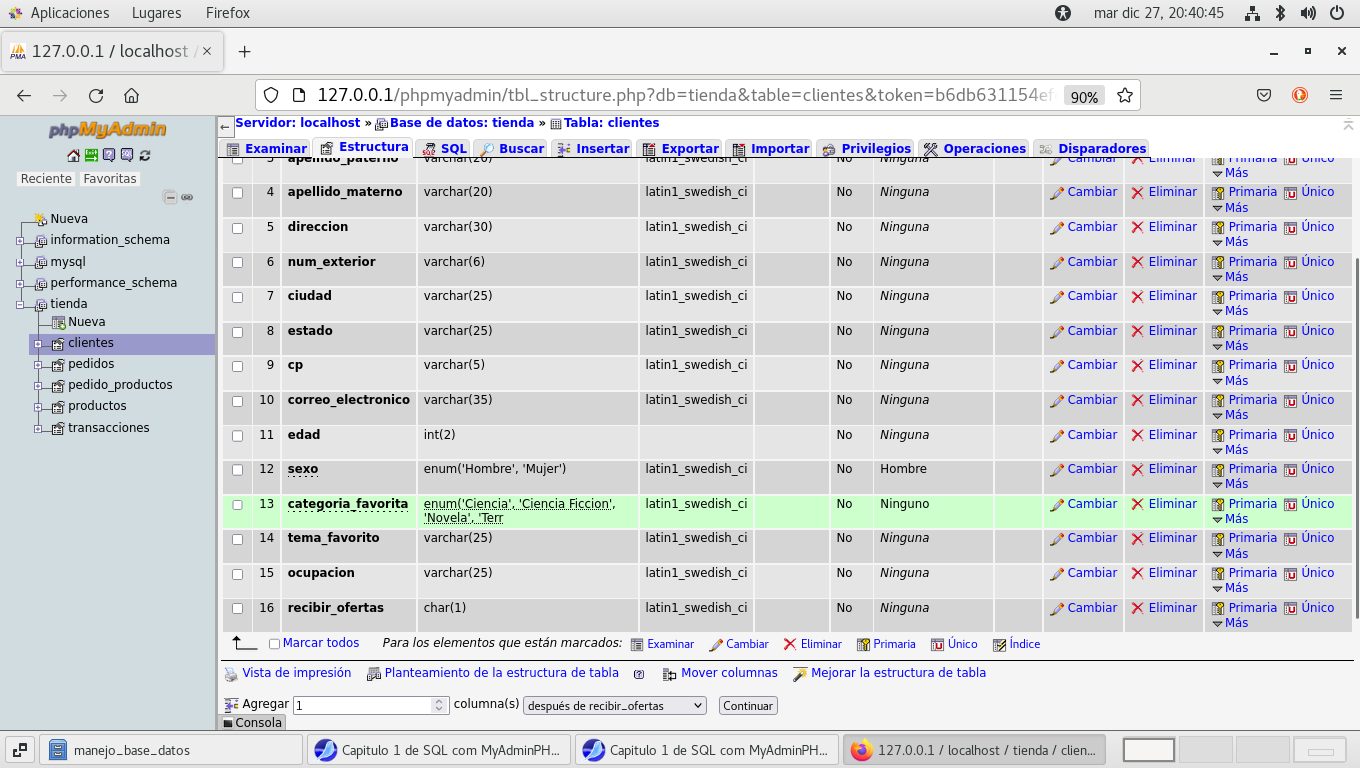
Modifiquemos otro campo, categoria_favorita, pasemos a enum con
las categorías : Ciencia, Ciencia Ficcion, Novela, Terror, Niños,
Aventura, Cocina, Ciclismo. Previsualizamos SQL
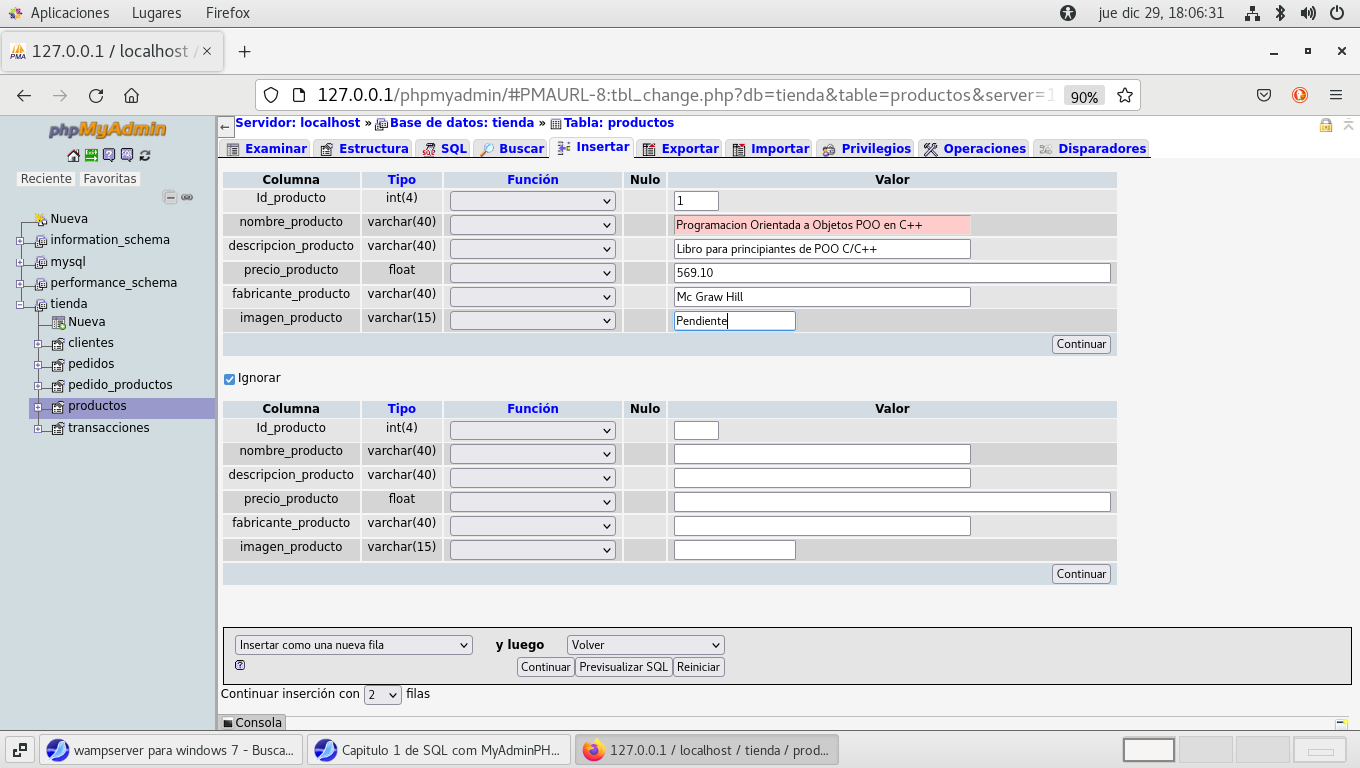
Ahora debemos de decidir que base de datos debemos de comenzar a
capturar:
para poder realizar cualquier transacción
debemos tener los datos de los producto en este caso libros, la
tabla es productos, luego los clientes, pedidos, transacción,
pedidos_productos, debemos de observar las "relaciones" entre las
tablas para decidir que tabla deber ser capturada y en que forma.
En la imagen inferior hemos comenzado a
introducir datos, sin embargo vemos que el campo nombre_producto
se ha marcado de un color diferente, esto se debe que la longitud
del texto es mas grande que la capacidad indicada en el campo, es
decir el campo es para 40 caracteres y estamos ingresando mas
caracteres que los indicados por el campo, varchar(40) estamos
ingresando mas de 40, lo que hacemos pues regresar a modificar la
estructura de la tabla antes de proseguir.
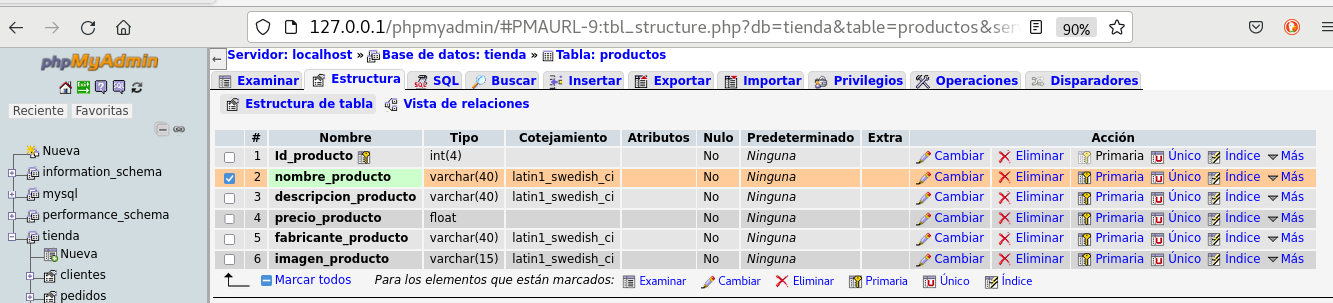
a continuación vemos que en estructura de la tabla productos
seleccione el campo nombre_producto, y sobre el botón
Cambiar:
inicialmente esta de esta manera, con 40 caracteres en el campo,
pasemos el 40 a 60:

cambio el valor por 60 caracteres de longitud y
agrego un comentario al campo, esto ultimo no es mas que opcional,
y se realiza una Previsualizacion SQL, para conocer como es el
comando de SQL para cambiar el tamaño de un campo.
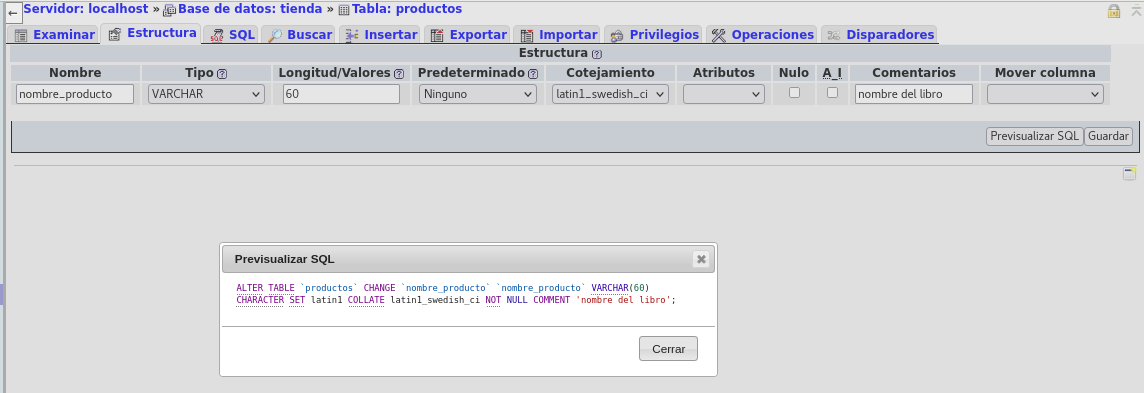
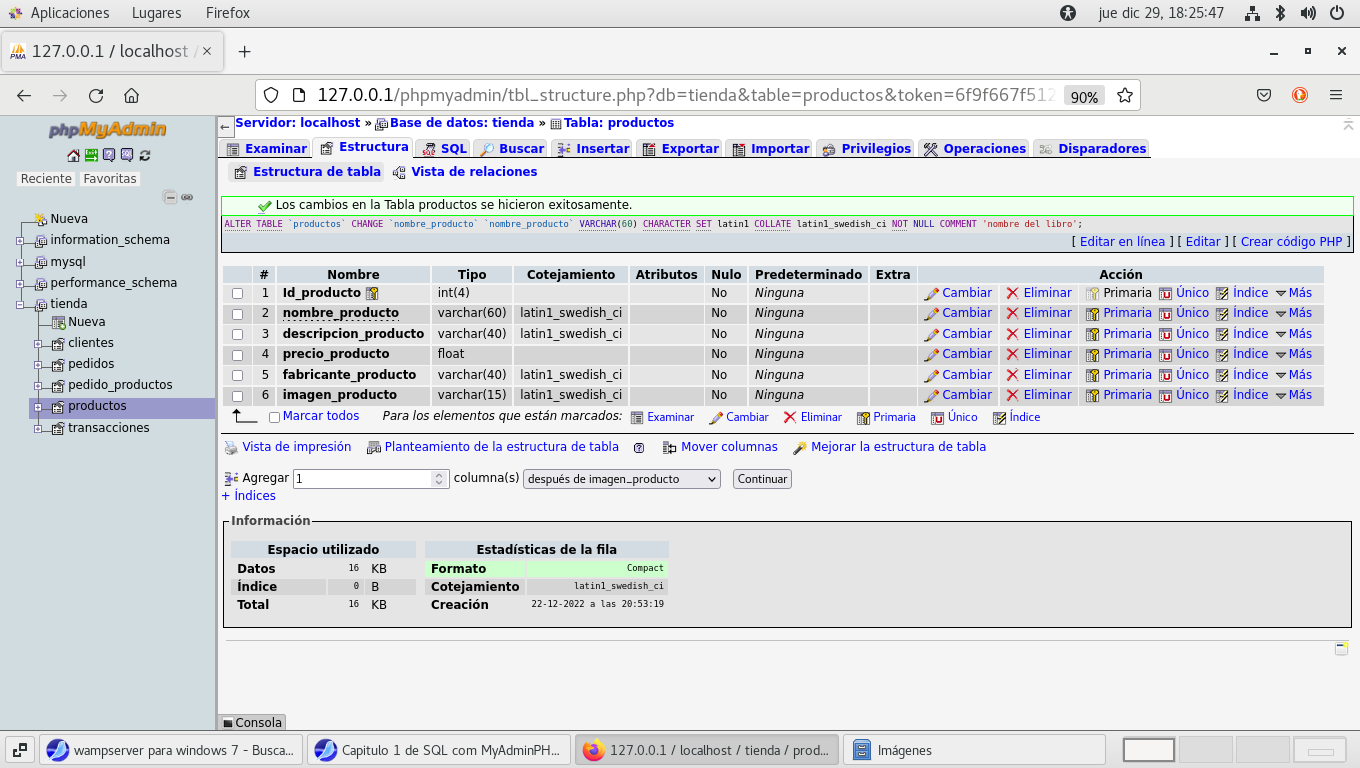
Al guardar los cambios:
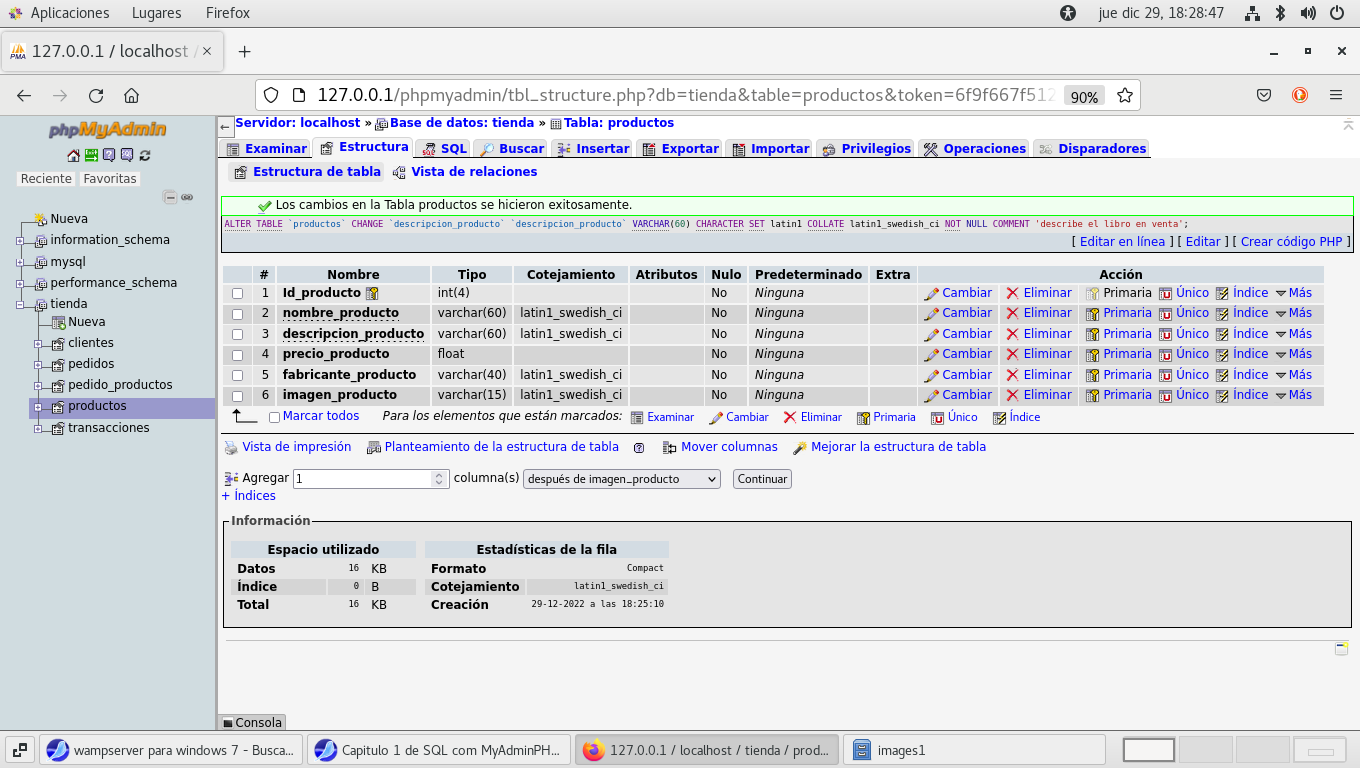
Cambiemos el siguiente campo que también esta restringido a 40
pasemos a 60, el alumno(a) debera de realizar este cambio, también
puede sugerir algún cambio, en la tabla como agregar campos o
modificar algo.
hay una observación que debo hacer hay una opción que tiene la
descripción Mejorar la estructura de tabla: 
esta opción nos ayudara de normalizar las tablas
si tienes duda como normalizar tu tabla usa esta sección y te dará
los pasos para normalizar la tabla hasta el tercer nivel de
normalizacion. También sugiero usar el sección vista de impresión.
Regresamos a Insertar para ingresar datos a la tabla, y
aplicamos en el botón Continuar
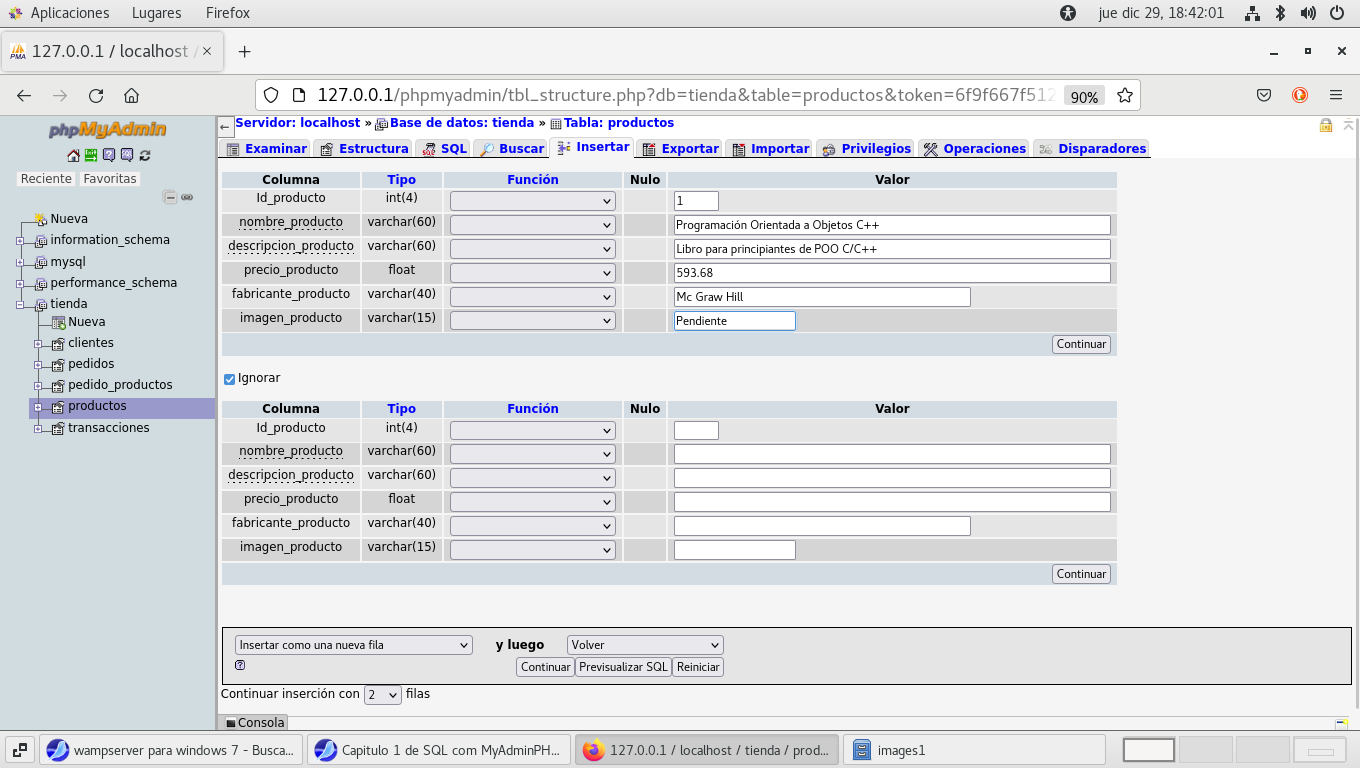
se ha realizado la insersion de datos de forma correcta, sin
errores.
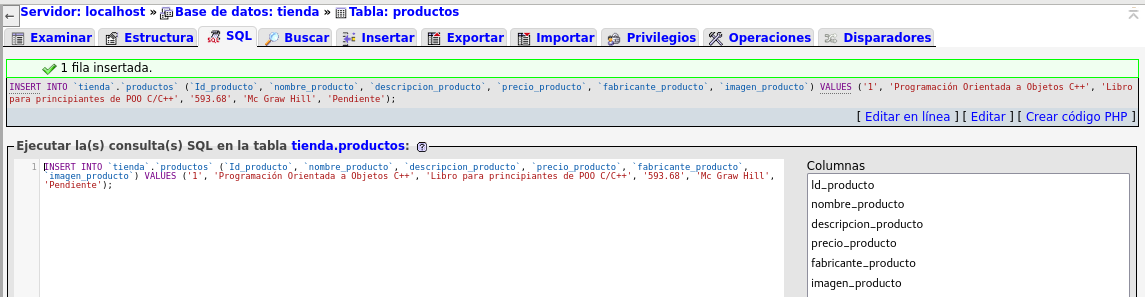
pasamos al separador Examinar:
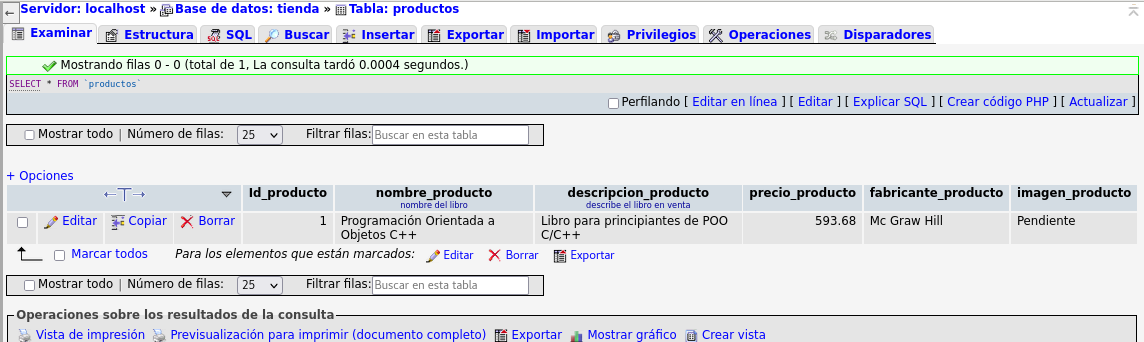
A todo esto las bases de datos en los sistemas de LINUX se
almacenan en el directorio: /var/lib/mysql
en windows lo hace asi C:\Documents and Settings\All Users\Datos
de programa\MySQL\MySQL Server 5.1\data
Se sugiere que los alumnos ingresen mas libros sean reales o
supuestos, analicen si hay algo que falte o se pueda agregar.
Por el momento he agregado mas datos de los
Libros, y he descubierto que tengo un error es la captura de
datos, en el registro numero 3 dice: SQL CON ORALE, y debe ser:
SQL CON ORACLE

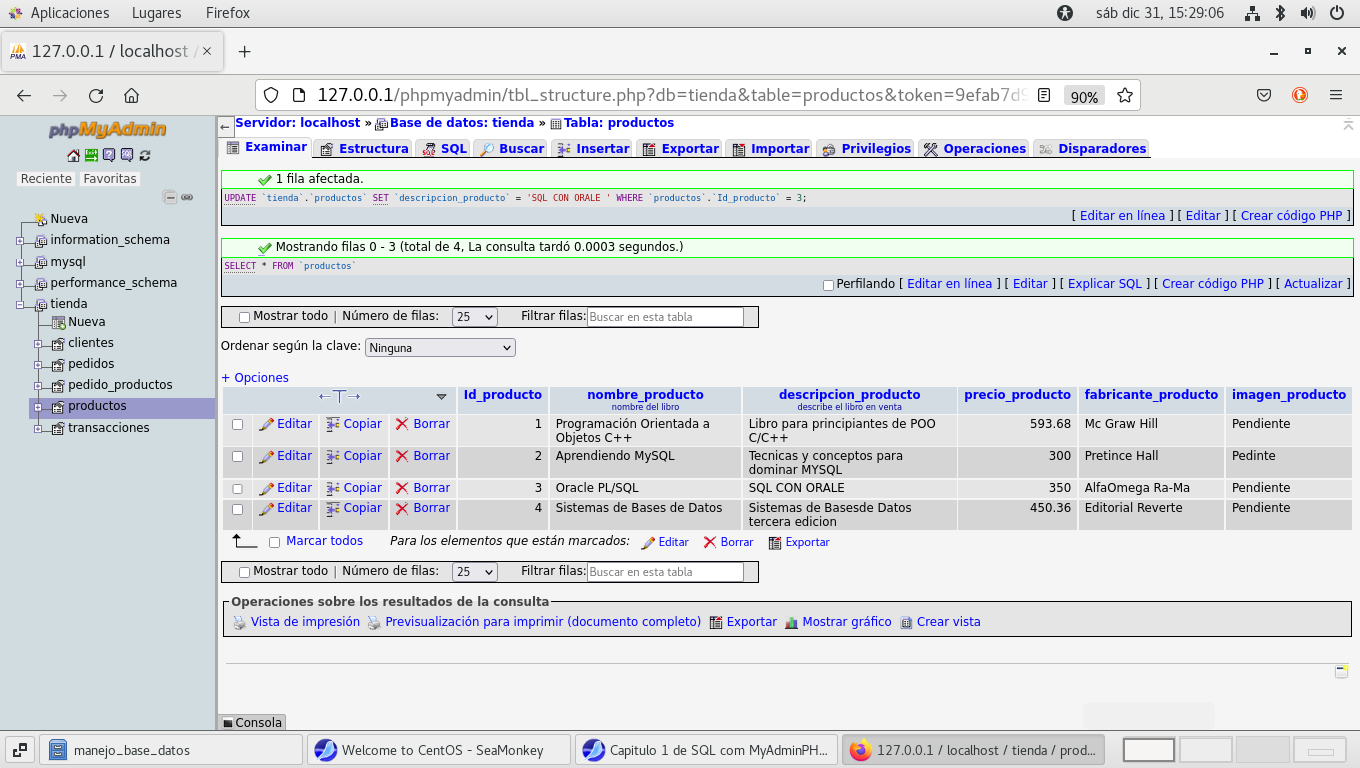
debemos marcar el registro, en casilla del lado izquierdo, se
debe ver de esta forma:
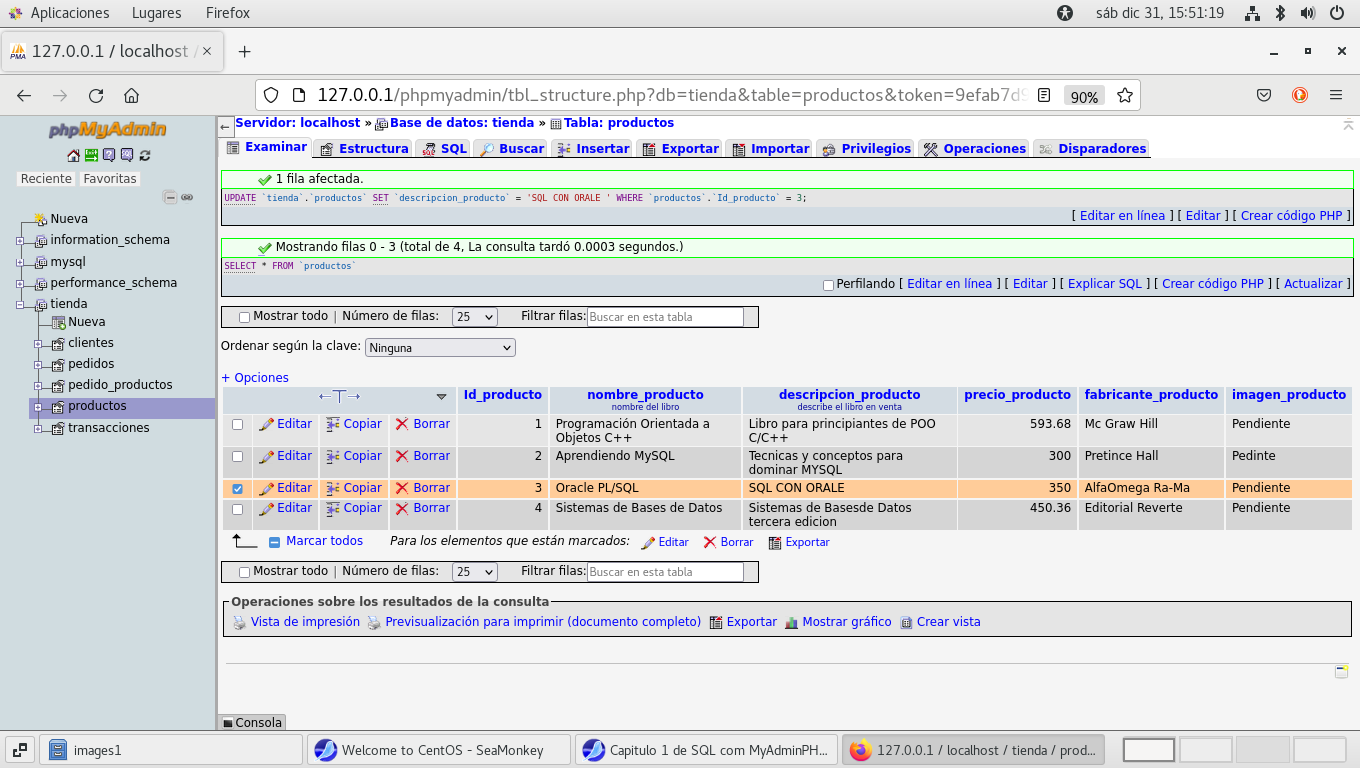
y seleccionamos editar:

a lo que nos llevara a la siguiente sección y realizamos la
corrección, y aplicamos el botón Previsualizar SQL, para observar
como se realiza el código en SQL :
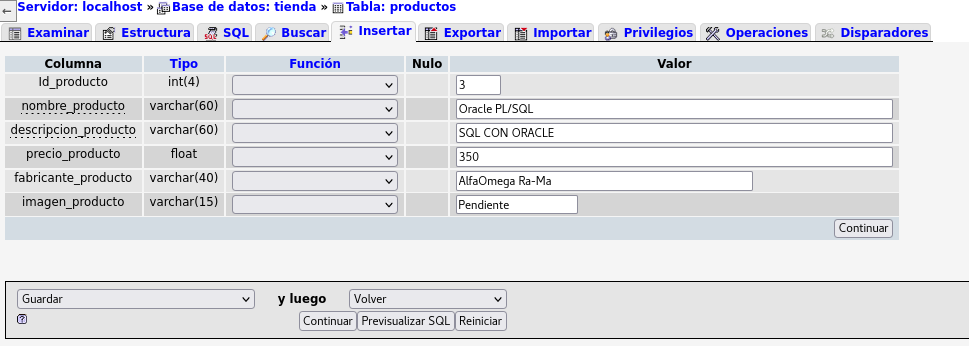
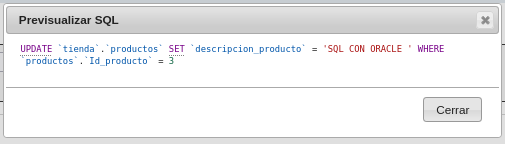
Veamos que se uso la instrucción UPDATE de la
base de datos tienda, la tabla productos SET nombre del campo
'descripcion_producto' y lo que fue actualizado 'SQL CON ORACLE'
WHERE de la tabla productos con el identificador =3, con update
podemos cambiar valores en los registros, ejemplo, si tomamos
varios libros de un pedido los vamos sumando el total de los
libros (la suma de los precios) cambiamos el campo del total del
pedido y realizamos UPDATE, con ello se actualiza el total de la
compra.
Esto lo debemos de ir considerando puesto que cuando realicemos
el programa que manipula las tablas ya sea desde una aplicación o
desde WEB debemos escribir estas instrucciones de desde la
aplicación o WEB para que se hagan los cambios necesarios en
mariaDB.
Ahora sobe el botón Continuar, quedara actualizado el registro.
A continuación usaremos la tabla clientes para
dar de alta a un cliente,
Luego debo de realizar una transacción porque el cliente me
solicita un libro, pues bien la transacción esta relacionada con
el pedido, aquí esta relacionado con el Id_cliente, y tiene el
Id_transaccion, en pedidos:
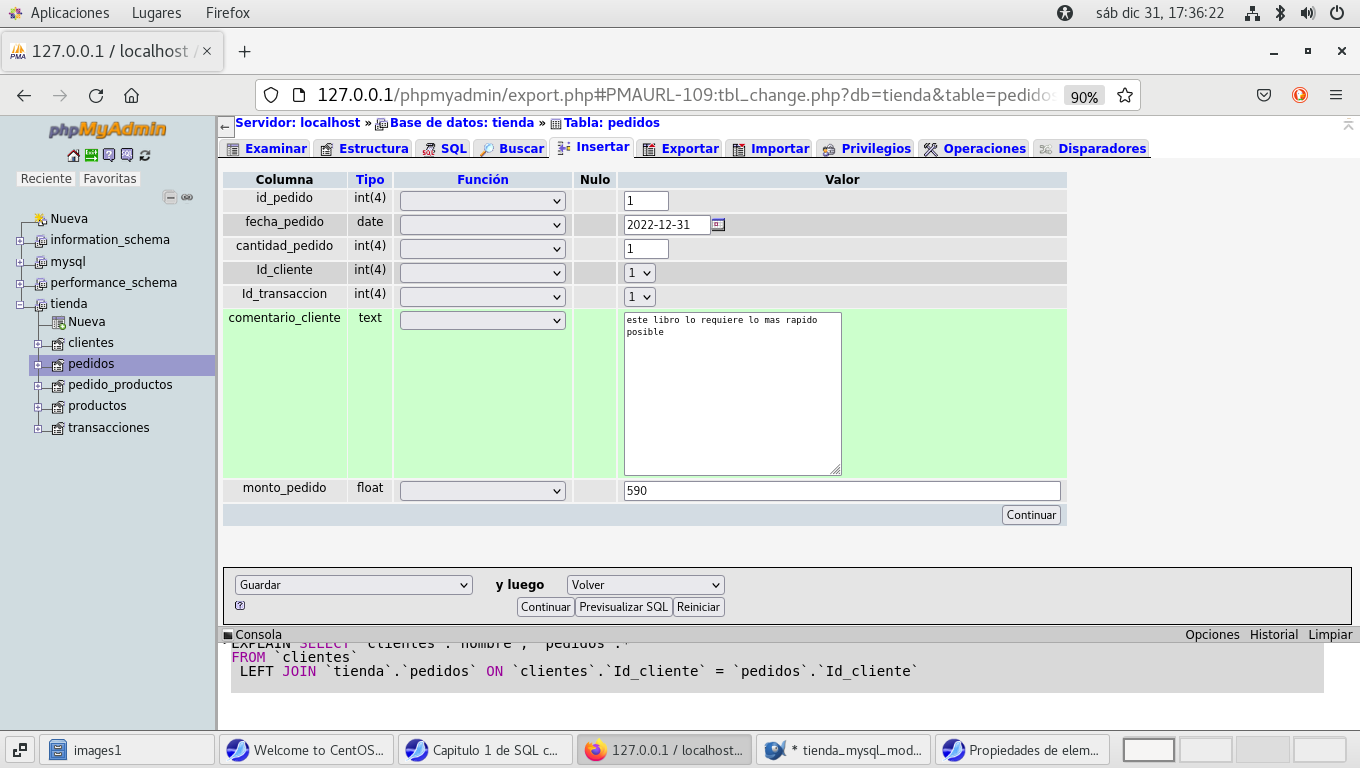
Los alumnos(as) deberán de crear una base de
datos que tengan al menos 2 claves primarias y claves foráneas,
del tópico que sea, el tema es libre, y enviar la estructura de la
base de datos / tablas, al correo indicado anteriormente.
Ejercicio de Base de
datos.
Se crearan las siguientes tablas en la base de datos llamada
escolar
Tabla estudiantes,
se requiere para administrar 1000 alumnos, cuyo numero deberá ser
incrementado de forma automatica, conteniendo los siguientes
campos:
ID numérico para 5 posiciones de
campo, siendo la clave primaria
Nombre texto con 20 posiciones de
campo
Apellido texto con 20 posiciones
de campo
Especialidad con 30 posiciones de
campo
Creditos numérico (el limite es
hasta el numero 500, tu decide que tipo de atributo le darás al
campo)
------------------------------------------------------------------------------------------------
Tabla aulas contendrá los
siguientes campos:
IDaula numérico para 5 posiciones
de campo, siendo la clave primaria PK
Edificio texto con 15 posiciones
de campo
Numeroaula numérico de 4 posiciones
de campo
Numeroasientos numérico de 4
posiciones de campo
Descripcionaula texto con 50
posiciones de campo
----------------------------------------------------------------------------------------------------
Tabla especialidades
contendrá los siguientes campos:
Especialidad texto con 30
posiciones de campo
Totalcreditos numérico de 4
posiciones de campo
Totalestudiantes numérico de 4
posiciones de campo
-------------------------------------------------------------------------------------------------------
Tabla cursos contendrá los
siguientes campos:
Departamento texto con 3
posiciones de campo, propiedad único (no permitido repetir)
Ncurso texto con 3 posiciones de
campo, propiedad único (no permitido repetir)
Descripcioncurso texto con 20
posiciones de campo
Cupoestudiantes numérico de 3
posiciones de campo
Nestudiantes numérico de 3
posiciones de campo
Ncreditos numérico de 1 posiciones
de campo
IDaula numérico de 5 posiciones de
campo (clave foranea "FK"de la tabla aulas)
----------------------------------------------------------------------------------------------------------
Tabla estudios contendrá
los siguientes campos:
IDestudiante numérico de 5
posiciones de campo
Departamento texto de 3 posición
de campo, clave primaria a la tabla cursos
Ncurso texto de 3 posiciones
de campo clave primaria a la tabla cursos
Grado texto de 1 posición de campo
(será A, B, C, D, E) que propiedad le aplicarías para seleccionar
entre una lista de valores
la clave primaria ID de la tabla estudiantes
es la clave externa para el campo IDestudiante de esta tabla (FK).
-----------------------------------------------------------------------------------------------------------
Tabla cambios contendrá los
siguientes campos:
Tipo texto de 1 posición de campo
Razon texto de 8 posiciones de
campo
Fecha fecha no null
Antiguedadestudiante numérico de 1
posición de campo
Antiguodepartamento texto de 3
posiciones de campo
Antiguocurso numérico de 3
posiciones de campo
Antiguogrado texto de 1 posiciones
de campo
Nuevoestudiante numérico de 5
posiciones de campo
Nuevodepartamento texto de 3
posiciones de campo
Nuevocurso numérico de 3
posiciones de campo
Nuevogrado texto de 1 posición de
campo
-------------------------------------------------------------------------------------------------------
Tabla errores contendrá los
siguientes campos:
Codigo numerico de 3 posiciones de
campo
Mensaje texto de 200 posiciones de
campo
Informacion texto de 100
posiciones de campo
-------------------------------------------------------------------------------------------------------
Tabla temporal contendrá
los siguientes campos:
Columnanumerica numérico de 3
posiciones de campo
Columnacaracter texto de 100
posiciones de campo
--------------------------------------------------------------------------------------------------------
Tabla debug contendrá los
siguientes campos:
Nlinea numérico de 3 posiciones de
campo
Texto texto de 100 posiciones de
campo
---------------------------------------------------------------------------------------------------------
Crear esta base de datos en DBDesigner, ya
teniedo el diseño captura la pantalla (en formato .jpg) y genera
el script en MySQL, envialos como evidencia al correo ya
mencionado, indicando tu nombre completo y con la descripción de:
ejercicio final unidad 1
Anexo 1 Codigo de barras
Proporcionamos una breve explicación sobre como
se usan los códigos de barras y sus estándares, no es una guia
extensa pero nos ayudaran a implementar una secuencia de códigos
de barras para artículos / servicios para simplificar nuestras
capturas en las Bases de Datos, Anexo1
Continuamos en el Capitulo 2
https://app.dbdesigner.net/
(1) https://www.oracle.com/mx/database/what-is-database/
(2) https://desarrolloweb.com/articulos/1054.php
(3) https://disenowebakus.net/tipos-de-datos-mysql.php
(4) http://sql.11sql.com/sql-valores-null.htm
(5) https://thedataschools.com/sql/default/
(6)
https://dev.mysql.com/doc/refman/8.0/en/binary-varbinary.html
(7)
https://www.adictosaltrabajo.com/2015/09/11/introduccion-a-indices-en-mysql/
(8) https://www.mysqltutorial.org/mysql-primary-key/
(9)
https://dev.mysql.com/doc/refman/8.0/en/example-auto-increment.html
(10)
https://www.mysqltutorial.org/mysql-unique-constraint/
(11) https://www.w3resource.com/mysql/mysql-full-text-search-functions.php#:~:text=FULLTEXT%20is%20the%20index%20type,ALTER%20TABLE%20or%20CREATE%20INDEX.
(12) https://platzi.com/clases/1566-bd/19791-formas-normales-en-db-relacionales/?gclid=EAIaIQobChMI1MnKlbCJ_AIVVAetBh2NNA9PEAAYASAAEgIoj_D_BwE&gclsrc=aw.ds
(13) https://dev.mysql.com/doc/refman/8.0/en/alter-table.html
(14)
https://www.cockroachlabs.com/blog/sql-add-constraint/
(15) https://www.ionos.mx/digitalguide/hosting/cuestiones-tecnicas/que-es-innodb/
InnoDB ha pasado de ser un subsistema de almacenamiento al motor
de almacenamiento de propósito general para MySQL. Su gran
fiabilidad, incluso a muy alto rendimiento, ha llevado a MySQL a
hacer de InnoDB el motor de almacenamiento predeterminado en las
versiones 5.6 y posteriores.
https://desarrolloweb.com/articulos/habilitando-innobd-en-mysql.html
https://www.filesuffix.com/es/extension/isam
(16) https://codigofacilito.com/articulos/motores-mysql
http://dan1456.blogspot.com/p/myisam-e-innodb_4.html
Especificadores de
formato para fechas
Especificador Descripcion
%a
Abbreviated weekday name
(Sun..Sat)
%b
Abbreviated month name
(Jan..Dec)
%c
Month, numeric (0..12)
%D
Day of the month with
English suffix (0th, 1st, 2nd, 3rd, …)
%d
Day of the month, numeric
(00..31)
%e
Day of the month, numeric
(0..31)
%f
Microseconds
(000000..999999)
%H
Hour (00..23)
%h
Hour (01..12)
%I
Hour (01..12)
%i
Minutes, numeric
(00..59)
%j
Day of year (001..366)
%k
Hour (0..23)
%l
Hour (1..12)
%M
Month name (January..December)
%m
Month, numeric (00..12)
%p
AM or PM
%r
Time, 12-hour (hh:mm:ss
followed by AM or PM)
%S
Seconds (00..59)
%s
Seconds (00..59)
%T
Time, 24-hour (hh:mm:ss)
%U
Week (00..53), where Sunday
is the first day of the week; WEEK() mode 0
%u
Week (00..53), where Monday
is the first day of the week; WEEK() mode 1
%V
Week (01..53), where Sunday
is the first day of the week; WEEK() mode 2; used with %X
%v
Week (01..53), where Monday
is the first day of the week; WEEK() mode 3; used with %x
%W
Weekday name (Sunday..Saturday)
%w
Day of the week
(0=Sunday..6=Saturday)
%X
Year for the week where
Sunday is the first day of the week, numeric, four digits; used
with %V
%x
Year for the week, where
Monday is the first day of the week, numeric, four digits; used
with %v
%Y
Year, numeric, four digits
%y
Year, numeric (two digits)
%%
A literal % character
%x
x, for any “x” not listed
above